Print(Hello, Brazil!): Uma Análise Quantitativa da Posse de Bolsonaro
Introdução
Durante períodos eleitorais, a discussão sobre métodos estatísticos sempre vem à tona devido à constante divulgação de pesquisas eleitorais. Em particular, a constante propagação de falácias pelo então candidato Jair Bolsonaro e a discrepância entre os resultados apontados pelas pesquisas e aqueles apurados nas urnas aumentaram muito a disconfiança sobre os métodos utilizados. Para mais detalhes a respeito da metodologia empregada em pesquisas eleitorais, recomendamos este artigo.
Aqui vamos expor o processo que percorremos ao realizar a análise contida nesta série. Para não deixar dúvidas aos mais desavisados, análise de texto não tem NADA A VER com pesquisas eleitorais. A potencialmente aparente semelhança que pode ter vindo à mente do leitor se deve somente ao contexto político em que métodos estatísticos estão sendo empregados. Claro, isso não implica que haja qualquer relação entre tais métodos.
Nossa intenção aqui é expor os resultados que obtivemos de uma maneira mais crua, tocando levemente em aspectos técnicos. Recomendamos o artigo para aqueles curiosos que leram algum dos nossos textos e também para quem quer usar o R para fins semelhantes. Sugerimos a ambos os grupos que façam o download do código, seja para fazer experimentos e extrair suas próprias conclusões a respeito dos discursos presidenciais ou ainda para examinar em maior detalhe os formatos-padrão de tabelas para bibliotecas importantes em análise de textos, como a quanteda, a tidytext e a stm.
Quatro Princípios em Análise Automatizada de Textos
A ideia de analisar muitos textos simultaneamente parece muito atrativa aos olhos de quem tem gosto pela leitura. Isso se deve à ‘promessa’ de aumentar o número de leituras. Porém, a análise quantitativa de um texto não substitui sua leitura. Este texto descreve algumas boas práticas para quem faz e também para quem interpreta análises quantitativas de textos. Colocamos para o leitor uma versão resumida dos 4 princípios apresentados na seção 2.
1.Todos os Modelos Quantitativos de Linguagem Estão Errados - Mas Alguns são Úteis: O processo de gerar dados em forma de texto é muito complicado e nem mesmo especialistas em linguística sabem ao certo como funcionam as estruturas de dependência nos, e entre os, diferentes níveis hierarquicos de um texto (capítulos, parágrafos, frases, palavras e etc). Entretanto, ainda conseguimos extrair informações e ideias úteis a partir de modelos quantitativos. Em suma, a qualidade do modelo é descrita pela sua capacidade de cumprir as tarefas para as quais é empregado
2.Métodos Quantitativos Ajudam Humanos e Não os Substituem: Métodos de análise quantitativa já demonstraram boa performance em uma grande variedade de problemas importantes. Contudo, tais técnicas não substituem o pensamento crítico e leitura cuidadosa feita pelos pesquisadores. De fato, conhecer a fundo os dados é essencial para se fazer uma boa análise
3.Não Existe um Método Globalmente Ótimo para Análise de Texto: Diferentes conjuntos de dados nos levam a diferentes perguntas, e cada pergunta merece atenção especial, sendo nescessárias técnicas e modelos (ou “famílias” destes) diferentes para cada propósito. O artigo citado acima também apresenta um resumo das técnicas usadas para alguns objetivos.
4.Validar, Validar, Validar: Esse princípio está muito relacionado à aplicação de modelos de machine learning para a análise de textos. Uma vez que não existe um método globalmente ótimo, é muito importante testar várias possibilidades e comparar seus desempenhos ao se fazer uma análise. É muito importante evitar usar resultados obtidos por um modelo não validado.
Colocando a Mão na Massa - Importação e Tratamento dos Dados
O primeiro passo para toda e qualquer análise é importar dados para sua plataforma favorita. Aqui, vamos usar uma base coletada no site da biblioteca do governo federal. Ela consiste dos discursos de posse dos presidentes Fernando Henrique Cardoso, Luiz Inácio Lula da Silva e Dilma Roussef, cada um em seus dois mandatos, Michel Temer e Jair Bolsonaro. Toda a análise é feita utilizando o RStudio e os pacotes que são carregados a seguir:
library(lexiconPT) # Análise de Sentimentos em português
library(tidyr) # formatação de dados
library(dplyr) # Tratamento dos gráficos
library(ggplot2) # Visualizações
library(igraph) # Fazer Grafos
library(ggraph) # Visualizar grafos no estilo ggplot
library(gridExtra) # Mostrando gráficos simultâneamente
library(tidytext) # Tratamento de texto (tabelas)
library(stringr) # Tratamento de texto (strings)
library(corpus) # StopWords
library(tm)
library(ggwordcloud) # Nuvens de palavras no estilo ggplot
library(knitr) # Markdown
library(kableExtra) # create a nicely formated HTML table
library(formattable) # for the color_tile function
library(tidyverse) # tudo de melhor para o R
library(forcats)
library(stm) # Modelagem de tópicos
library(quanteda) # Tratamento de texto
library(drlib) # função reorder... que é importante para a beleza dos gráficos
library(radarchart) # Gráficos radarIniciamos carregando a nossa base de dados, juntamente com outras tabelas que contém a traduções dos textos para a língua inglesa. Essas traduções serão importantes e uma lista de stopwords, que são palavras que ocorrem naturalmente muitas vezes em uma língua e assim acabam viesando este tipo de análise. Artigos como “a” e “o” e preposições como “de” e “para” são exemplos de palavras que tendem a aparecer muitas vezes em qualquer texto escrito em português.
dados <- read.csv("dados.csv", stringsAsFactors = FALSE)[, -1]
names(dados) <- c("V1", "presver", "ano", "presidente")
traduc <- read.csv("traducao.csv", stringsAsFactors = FALSE)
trnlst <- read.csv("trnslt.csv", stringsAsFactors = FALSE)
stp_wrds <- corpus::stopwords_pt
traduc$translatedText[4] <- "come away, flame this dream"Agora, vamos definir duas funções que serão nescessárias para o nosso trabalho. A primeira delas é projetada para o tratamento dos dados, colocando todas as palavras em letra minúscula para que não tenhamos distinções indesejadas. Além disso, removemos pontuações e outras “sujeiras” dos dados. A segunda função tem o propósito de substituir a função bind_tf_idf do pacote tidytext. Não ousaremos dizer que a função está errada sem olhar seu código, entretanto acreditamos que ela atribui TF-IDF zero para todas as palavras que aparecem em todos os documentos. Recomendamos que confiram seus resultados ao usar bind_tf_idf.
extrai_palavras <- function(df, opt) {
## letra minuscula
df[, 1] <- tolower(df[, 1])
## tira quebras de linha e stopwords
for (i in seq_along(df$V1)) {
df[i, 1] <- gsub("[\n“”–—]", " ", removeWords(df[i, 1], stp_wrds))
}
## cria vetor de palavras
palavras <- unlist(str_split(df$V1[1:NROW(df)], " +"))
# tira pontuação
palavras <- (removePunctuation(palavras))
# tira espaços vazios
palavras <- palavras[str_count(palavras) > 1]
## cria contagem
if (opt == "count") {
palavras_count <- table(palavras)
return(palavras_count)
}
## unique
if (opt == "unique") {
return(unique(palavras))
}
}
## Função caseira para calcular o TF-IDF
tf_idf_caseirao <- function(tfrases) {
tfrases <- tfrases %>% mutate(idf = 0)
for (i in 1:nrow(tfrases)) {
tfrases$idf[i] <- 1 / filter(tfrases, word == tfrases$word[i]) %>% nrow()
}
tfrases <- tfrases %>% mutate(tf_idf = n * idf)
}Agora, usamos a função extrai_palavras para obter os data frames tab_frase e tidyfrase, que estão nos formatos ideais para trabalharmos com os pacotes necessários. Vamos usá-los em grande parte do trabalho.
AVISO: Abrir a tabela tab_frase pode travar seu computador!
## TABELA TIDYFRASE
# fazendo a tabela de ocorrencias de palavras por frase
tab_frase <-
data.frame(
frases = unlist(str_split(dados[1, 1], "[.]")),
stringsAsFactors = FALSE,
doc = rep(dados$ano[1]),
pres = rep(dados$presidente[1])
)
for (i in 2:NROW(dados)) {
tab_frase <- rbind(
tab_frase,
data.frame(
frases = str_split(dados[i, 1], "[.]")[[1]],
stringsAsFactors = FALSE,
doc = rep(dados$ano[i]),
pres = rep(dados$presidente[i])
)
)
}
tab_frase[, 1] <- removePunctuation(tab_frase[, 1])
aux <-
matrix(0,
nrow = nrow(tab_frase),
ncol = length(extrai_palavras(dados, "unique"))
)
names(aux) <- extrai_palavras(dados, "unique")
tab_frase <- cbind(tab_frase, aux)
names(tab_frase) <-
c("frases", "docs", "presidas", extrai_palavras(dados, "unique"))
nomes <- names(tab_frase)
tab_frase[-c(163, 338, 548), ] # frases so com espaco
# contando as palavras por frase
for (i in seq_along(tab_frase[, 1])) {
x <- as.data.frame(table(unlist(str_split(tab_frase[i, 1], " "))),
stringsAsFactors = FALSE
)[-1, ]
for (j in seq_along(x[, 1])) {
cnt_aux <- which(nomes == x[j, 1])
tab_frase[i, cnt_aux] <- x[j, 2]
}
}
tidyfrase <- tab_frase %>% select(frases, docs, presidas)
tidyfrase <- tidyfrase %>% mutate(nfrase = row_number())
tidyfrase <- tidyfrase %>% unnest_tokens(word, frases)
tidyfrase <- tidyfrase %>% filter(!(word %in% stp_wrds))
# pode ser feito direto com dados tb!
un_frases <- tab_frase %>%
unnest_tokens(word, frases) %>%
count(docs, word, sort = TRUE)
# find the words most distinctive to each document
tf_frases <- un_frases %>%
bind_tf_idf(word, docs, n) %>%
arrange(desc(tf_idf))Primeiras Vizualizações - Nuvens de Palavras
Agora vamos iniciar nosso passeio pelos dados. O caminho que iremos tomar é de fora para dentro. Isto é, começamos respondendo perguntas simples como “Quantas palavras diferentes foram ditas em cada fala?” e depois buscaremos respostas para, por exemplo, “Como medir a similaridade entre dois textos?” e “Quais são os tópicos predominantes em discursos presidenciais?”.
Começamos com nuvens de palavras mostrando as 30 palavras mais faladas em cada um dos discursos que analisaremos. Observe que, sem os títulos em cada gráfico, fica difícil capturar as diferenças entre os discursos. Parece que existem palavras, como “povo”, “Brasil” e “país” são quase obrigatóriamente repetidas muitas vezes no discurso inaugural de um presidente.
# BASEADA NA FREQUENCIA
for (i in 1:nrow(dados)) {
aux <- arrange(as.data.frame(extrai_palavras(dados[i, ], "count")), desc(Freq))
(ggplot(aux[1:30, ], aes(label = palavras, size = Freq)) +
geom_text_wordcloud() +
scale_size_area(max_size = 10) +
ggtitle(paste("Nuvem de frequência no discurso de", as.character(dados$ano[i]), sep = " ")) +
theme_minimal()) %>% print()
}







Os próximos gráficos também são nuvens de palavras, porém carregam diferenças em relação às vizualizações anteriores. A primeira delas é a função utilizada. Embora sejam ambas da biblioteca ggwordcloud, a primeira se comporta como uma opção para o layer geom do pacote ggplot2 e se encaixa perfeitamente com os outros recursos desse pacote. Enquanto isso, a função ggwordcloud2 tem o intuito de produzir resultados similares aos obtidos usando o pacote wordcloud2. Além disso, no ’chunk acima usamos o ranqueamento de uma palavra com relação à frequência para determinar se uma palavra apareceria ou não na nuvem de palavras. Abaixo, o critério é outro. Calculamos a média e o desvio padrão da frequência de palavras no texto e escolhemos as palavras com frequência maior ou igual à média mais duas vezes o desvio padrão.
## Nuvem - desvio padrão
for (i in 1:nrow(dados)) {
aux <- arrange(as.data.frame(extrai_palavras(dados[i, ], "count")), desc(Freq))
med <- mean(aux$Freq)
sd <- sd(aux$Freq)
aux <- aux %>% filter(Freq - med > 2 * sd)
ggwordcloud2(aux) %>% print()
}







Mil Jeitos de Contar Palavras
As tabelas a seguir apresentam algumas medidas referentes ao número de palavras faladas em cada discurso e por cada presidente. A coluna num_words apresenta o número total de palavras em cada instância. Além disso, a coluna uniq apresenta o número de palavras distintas em cada contexto e a coluna stp contém o número de stopwords. Finalmente, a coluna rep contém a razão uniq/num_words. De certa forma, o resultado dessa conta mede a variedade linguística em um documento.
Pela primeira vez, estamos dividindo a análise em duas perspectivas. Comparação por discursos ou presidentes. Esses dois tipos de abordagem vão ser amplamente aplicados daqui pra frente, às vezes dando lugar a um olhar mais geral. Aqui é importante destacar que para alguns fins, será importante duplicar as medidas em relação aos presidentes Temer e Bolsonaro, pois estes tiveram apenas um discurso de posse, enquanto FHC, Lula e Dilma tiveram dois.
De maneira simplificada, a nescessidade de duplicar as estatísticas de Temer e Bolsonaro é dada pelas comparações que fazemos. Por exemplo, num contexto em que estamos verificando quais palavras foram mais faladas por CADA presidente, essa ‘gambiarra’ não é nescessária pois, de qualquer maneira, a ordenação dessas estatísticas seria a mesma e a diferença entre elas proporcional. Por outro lado, num contexto em que investigamos quantas vezes cada presidente falou uma determinada palavra, aí sim é indispensável que alteremos as estatísticas para preservar a justiça na comparação ENTRE presidentes.
Uma outra alternativa para lidar com o problema da comparação ENTRE presidentes seria calcular a frequência relativa de uma palavra nas falas de um presidente, assim, a potencial maior ocorrência das palavras ditas por Lula, Dilma e FHC se ‘dissolve’ no maior número total de palavras ditas pelos mesmos.
# contagem total de palavras sem retirar stopwords
full_word_count <- dados %>%
unnest_tokens(word, V1) %>%
group_by(ano) %>%
summarise(num_words = n(), uniq = length(unique(word)), stp = length((word %in% stp_wrds)[word %in% stp_wrds == TRUE]), rep = length(unique(word)) / n()) %>%
arrange(desc(num_words))
full_word_count %>%
ungroup(num_words, ano) %>%
mutate(num_words = color_tile("white", "lightgray")(num_words)) %>%
mutate(stp = color_tile("white", "lightpink")(stp)) %>%
mutate(uniq = color_tile("white", "lightblue")(uniq)) %>%
mutate(rep = color_tile("white", "lightgreen")(rep)) %>%
kable("html", escape = FALSE, align = "c", caption = "Total de Palavras por Discurso") %>%
kable_styling(
bootstrap_options =
c("striped", "condensed", "bordered"),
full_width = FALSE
)| ano | num_words | uniq | stp | rep |
|---|---|---|---|---|
| 2015 | 4561 | 1468 | 1994 | 0.3218592 |
| 2003 | 3883 | 1440 | 1721 | 0.3708473 |
| 2007 | 3755 | 1347 | 1636 | 0.3587217 |
| 2011 | 3617 | 1231 | 1574 | 0.3403373 |
| 1995 | 3266 | 1227 | 1485 | 0.3756889 |
| 2016 | 2744 | 1017 | 1231 | 0.3706268 |
| 1999 | 2633 | 1044 | 1215 | 0.3965059 |
| 2019 | 990 | 489 | 446 | 0.4939394 |
# contagem total de palavras sem retirar stopwords
full_word_count <- dados %>%
unnest_tokens(word, V1) %>%
group_by(presidente) %>%
summarise(num_words = n(), uniq = length(unique(word)), stp = length((word %in% stp_wrds)[word %in% stp_wrds == TRUE]), rep = length(unique(word)) / n()) %>%
arrange(desc(num_words))
full_word_count %>%
ungroup(num_words, presidente) %>%
mutate(num_words = color_tile("white", "lightgray")(num_words)) %>%
# mutate(presidente = color_bar("lightgray")(presidente)) %>%
mutate(stp = color_tile("white", "lightpink")(stp)) %>%
mutate(uniq = color_tile("white", "lightblue")(uniq)) %>%
mutate(rep = color_tile("white", "lightgreen")(rep)) %>%
kable("html", escape = FALSE, align = "c", caption = "Total de Palavras por Presidente") %>%
kable_styling(
bootstrap_options =
c("striped", "condensed", "bordered"),
full_width = FALSE
)| presidente | num_words | uniq | stp | rep |
|---|---|---|---|---|
| dilma | 8178 | 2165 | 3568 | 0.2647347 |
| lula | 7638 | 2251 | 3357 | 0.2947107 |
| fhc | 5899 | 1898 | 2700 | 0.3217494 |
| temer | 2744 | 1017 | 1231 | 0.3706268 |
| bolsonaro | 990 | 489 | 446 | 0.4939394 |
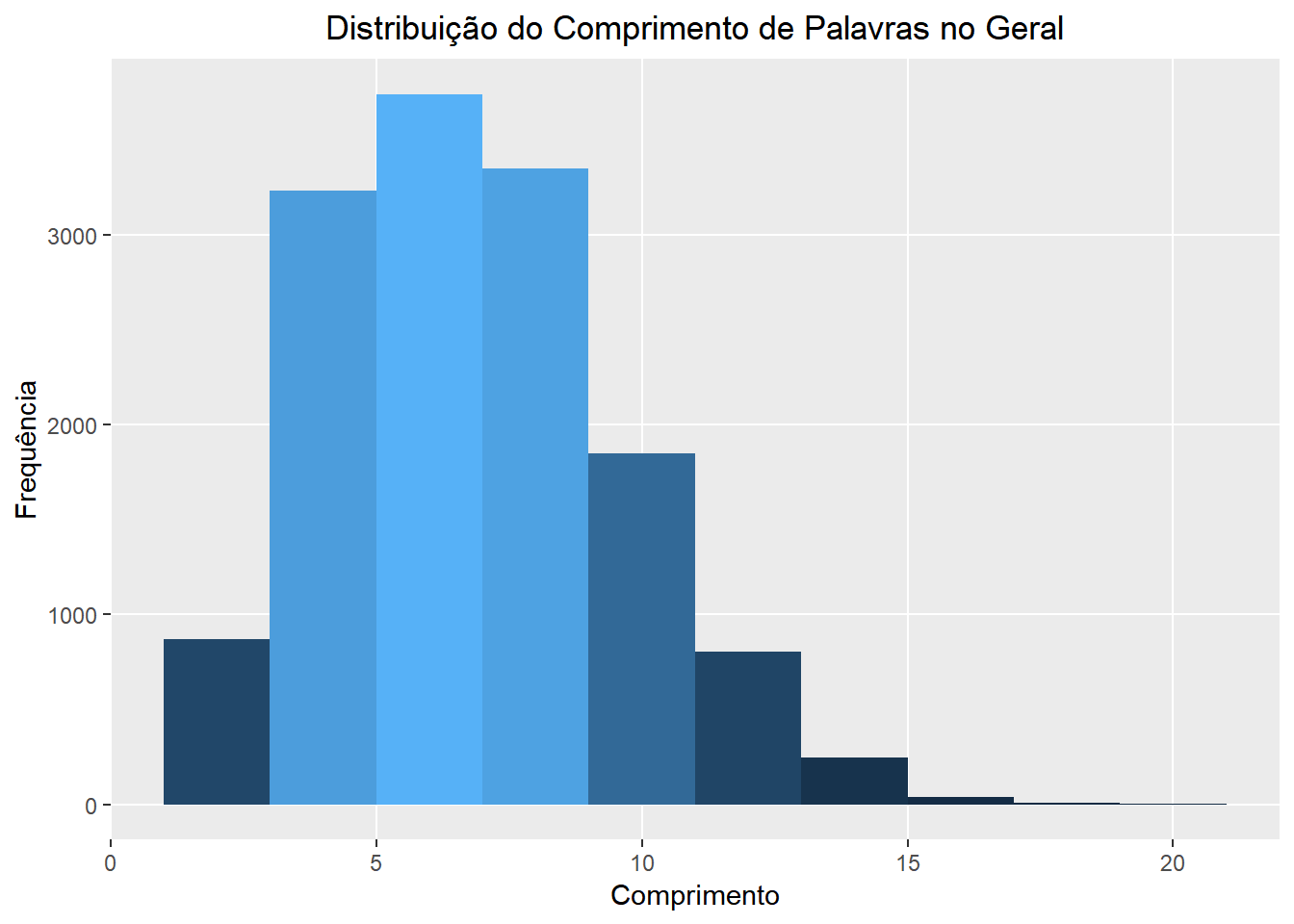
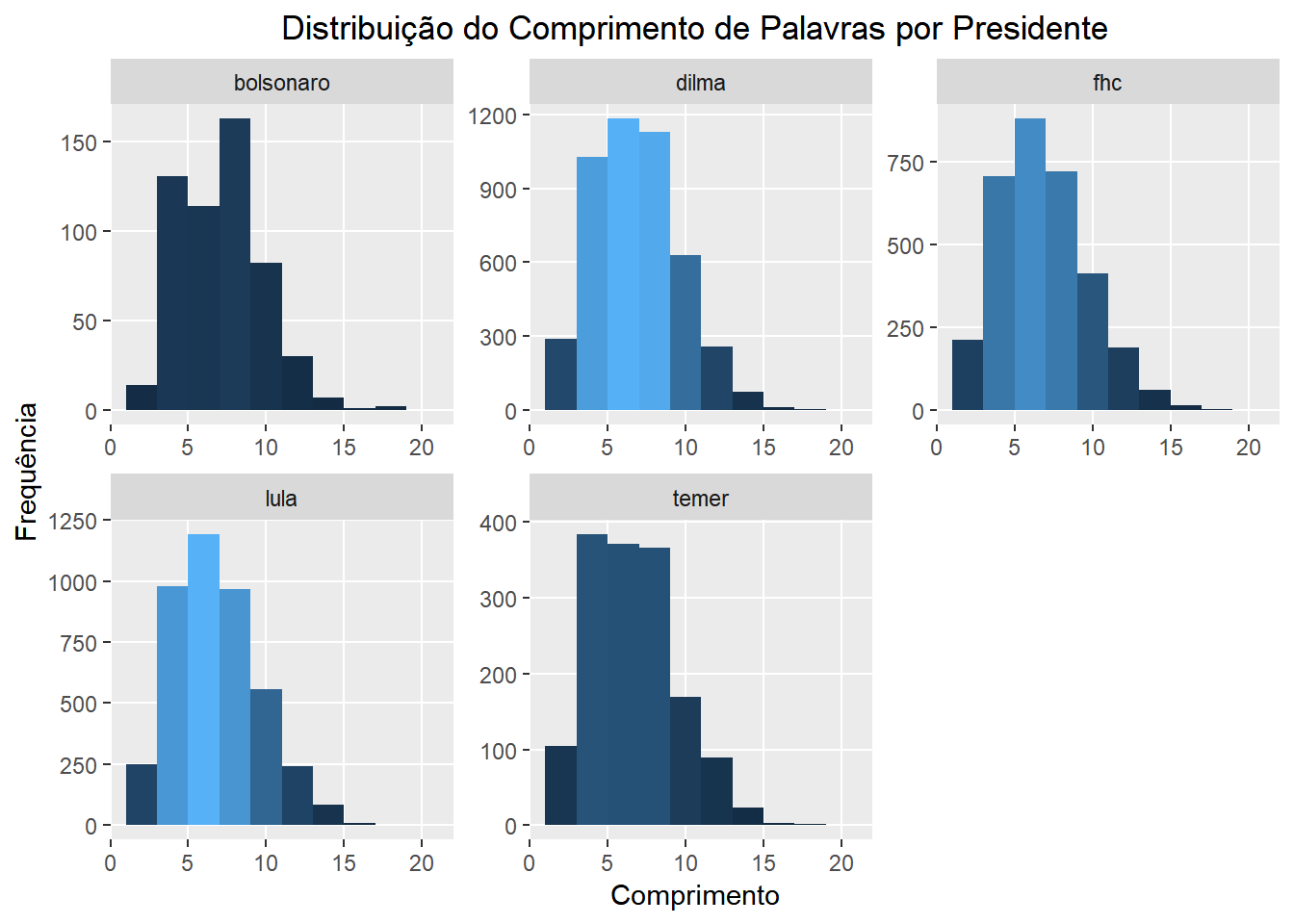
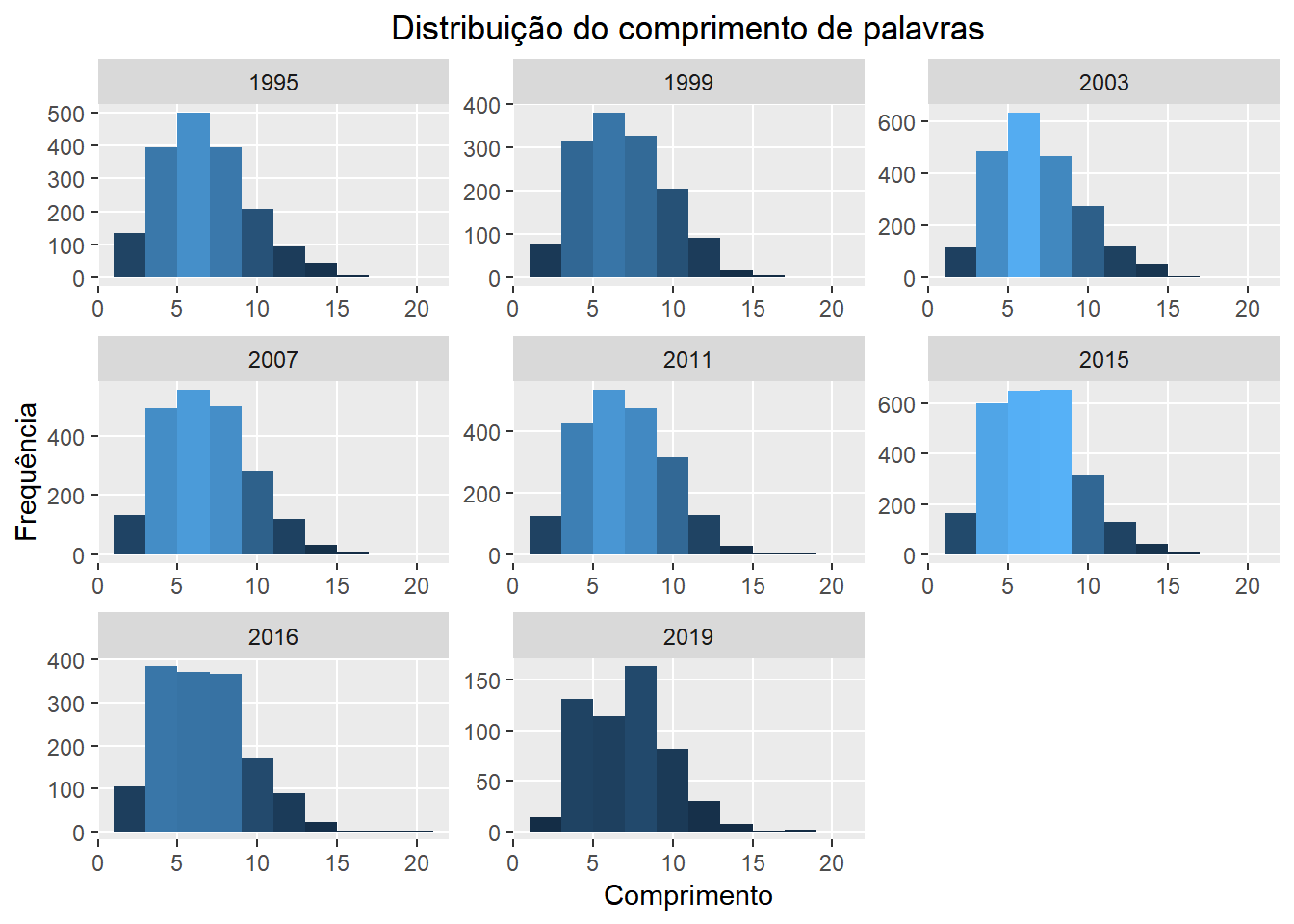
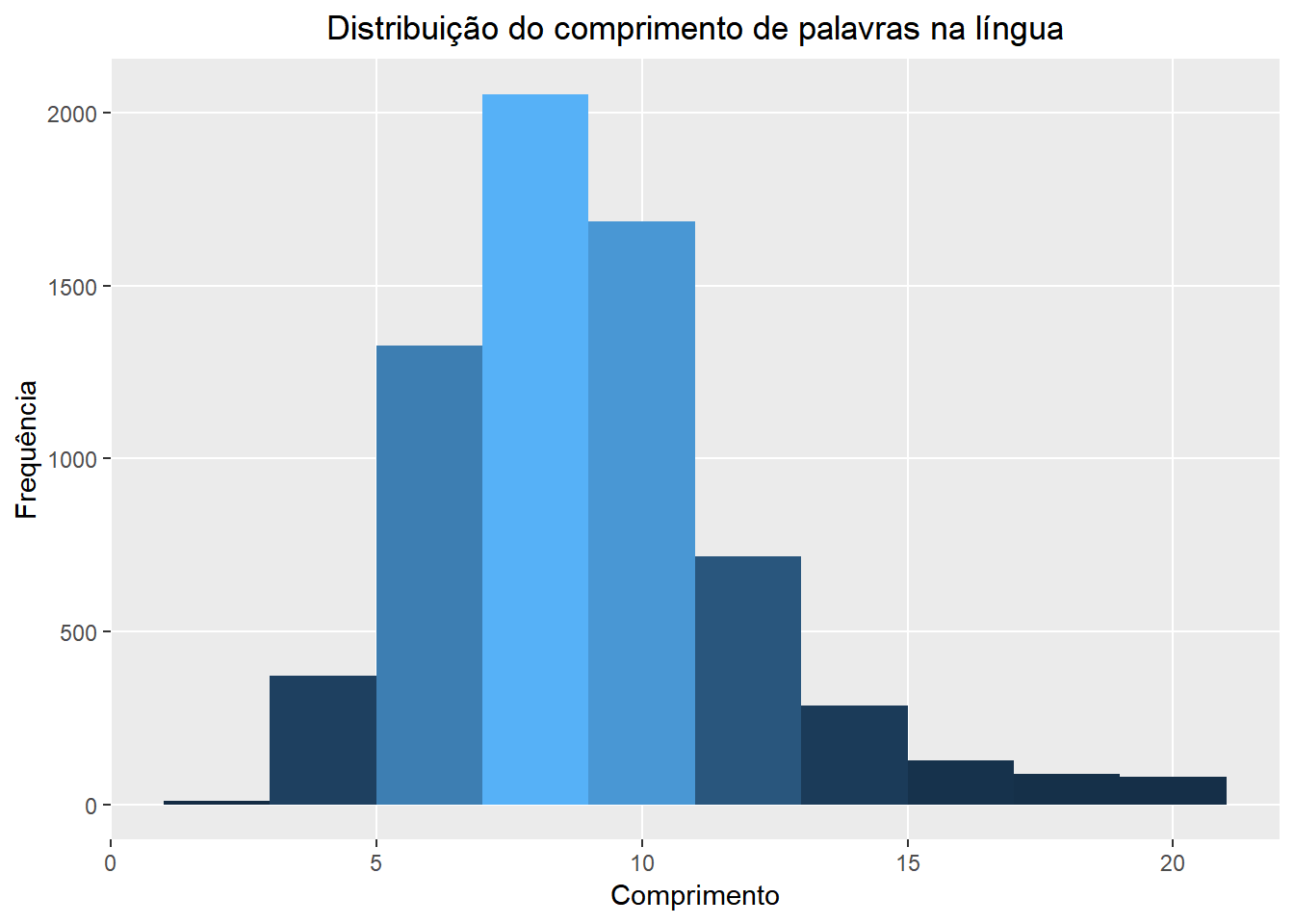
Agora que já sabemos quantas palavras foram ditas nas ocasiões estudadas e temos uma idéia sobre a quantidade de repetição em cada uma, vamos reconhecer que ainda não sabemos quase nada sobre o que de fato foi dito. Em seguida, queremos ter uma visão geral sobre o comprimento das palavras utilizadas. Para isso, comparamos as distribuições dessa quantidade no geral, em cada discurso, de cada presidente, e na língua portuguesa. Obtivemos uma aproximação para a distribuição geral na língua através dos dados sentiLex_lem_PT02 que estão disponíveis juntamente com o pacote lexiconPT.
Nas vizualizações a seguir temos a distribuição do comprimento das palavras conforme mencionado acima. A altura de cada barra representa o número de palavras com um certo número de letras. Enquanto isso, a cor de uma barra representa o número de termos distintos com aquele comprimento que foram ditos. Quanto mais clara a barra, mais termos diferentes.
#####################
# word length dist
word_lengths <- dados %>%
unnest_tokens(word, V1) %>%
mutate(word_length = nchar(word)) %>%
filter(!(word %in% stp_wrds))
word_lengths %>%
ggplot(aes(word_length),
binwidth = 1
) +
geom_histogram(aes(fill = ..count..),
breaks = seq(1, max(word_lengths$word_length), by = 2),
show.legend = FALSE
) +
labs(x = "Comprimento", y = "Frequência") +
ggtitle("Distribuição do Comprimento de Palavras no Geral") +
theme(
plot.title = element_text(hjust = 0.5),
panel.grid.minor = element_blank()
)
#####################
# word length dist por presidente
word_lengths %>%
ggplot(aes(word_length, fill = presidente),
binwidth = 1
) +
geom_histogram(aes(fill = ..count..),
breaks = seq(1, max(word_lengths$word_length), by = 2),
show.legend = FALSE
) +
facet_wrap(~presidente, scales = "free", labeller = labeller(presidas = c(bolsonaro = "Bolsonaro", dilma = "Dilma", fhc = "FHC", lula = "Lula", temer = "Temer"))) +
labs(x = "Comprimento", y = "Frequência") +
ggtitle("Distribuição do Comprimento de Palavras por Presidente") +
theme(
plot.title = element_text(hjust = 0.5),
panel.grid.minor = element_blank()
)
# word length dist por doc
word_lengths %>%
ggplot(aes(word_length, fill = ano),
binwidth = 1
) +
geom_histogram(aes(fill = ..count..),
breaks = seq(1, max(word_lengths$word_length), by = 2),
show.legend = FALSE
) +
facet_wrap(~ano, scales = "free") +
labs(x = "Comprimento", y = "Frequência") +
ggtitle("Distribuição do comprimento de palavras") + theme(
plot.title = element_text(hjust = 0.5),
panel.grid.minor = element_blank()
)
## Comparando dentro da lingua usando a tabela sentilex
distpcomp <- sentiLex_lem_PT02 %>% as.data.frame() %>% select(term) %>% mutate(tam = nchar(term))
distpcomp %>%
ggplot(aes(tam, fill = ano),
binwidth = 1
) +
geom_histogram(aes(fill = ..count..),
breaks = seq(1, max(word_lengths$word_length), by = 2),
show.legend = FALSE
) +
ggtitle("Distribuição do comprimento de palavras na língua") +
labs(x = "Comprimento", y = "Frequência") +
theme(
plot.title = element_text(hjust = 0.5),
panel.grid.minor = element_blank()
)
As próximas perguntas que surgem naturalmente são quais palavras foram mais ditas e quando isso aconteceu. O gráfico a seguir mostra quais foram as palavras mais faladas no total e a sua distribuição por discurso.
P.S: O gráfico também fica bonito dividindo por presidente ;)
####################
# total de ocorrencia de palavras
plot_total <- tf_frases %>%
group_by(word) %>%
mutate(total = sum(n), discs = length(docs)) %>%
filter(str_count(word) > 3) %>%
ungroup()
plot_total %>%
mutate(word = reorder(word, total)) %>%
filter(!(word %in% stp_wrds)) %>%
group_by(word) %>%
filter(total > 30) %>%
ggplot() +
geom_col(aes(word, n, fill = as.factor(docs))) +
scale_fill_brewer(type = "qual", palette = "Dark2") +
theme(
plot.title = element_text(hjust = 0.5),
panel.grid.major = element_blank()
) +
xlab("") +
ylab("Frequência") +
ggtitle("Palavras mais Frequentes no Geral") +
coord_flip() +
theme(
plot.subtitle = element_text(vjust = 1),
plot.caption = element_text(vjust = 1)
) + labs(x = NULL, fill = "Ano")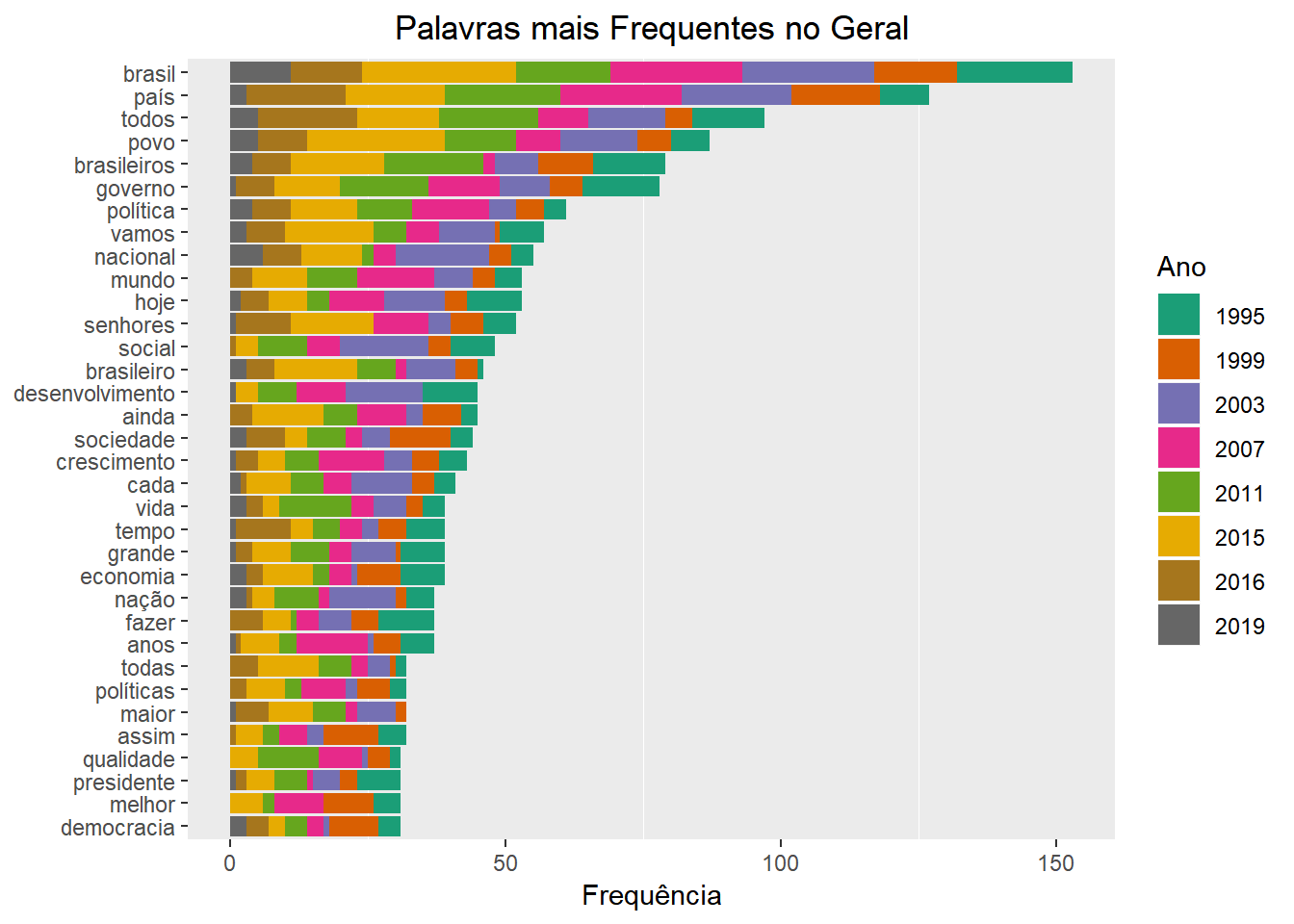
Uma boa maneira de se vizualizar distribuições de números absolutos é o gráfico de radar. Abaixo temos as distribuições das frequências das palavras “governo” e “brasileiros”. Aqui temos um bom exemplo de uma situação em que é indispensável duplicar as medidas de Temer e Bolsonaro.
palavras_chave2 <- c("governo", "brasileiros", "mulheres")
radartab <- tidyfrase %>%
filter(word %in% palavras_chave2) %>%
count(word, presidas, sort = TRUE) %>%
mutate(n = n + (presidas == "temer" | presidas == "bolsonaro") * n) %>%
as.data.frame()
for (i in 1:nrow(radartab)) {
if (radartab$presidas[i] == "bolsonaro" | radartab$presidas[i] == "temer") {
radartab$n[i] <- 2 * radartab$n[i]
}
}
# radartab<- radartab %>% mutate(percent = (as.numeric(n)/ 15) * 100 ) %>%
radartab <- radartab %>%
spread(word, n) %>%
select(presidas, governo, brasileiros, mulheres)
chartJSRadar(radartab,
showToolTipLabel = FALSE,
main = "Distribuição de Palavra por Presidente"
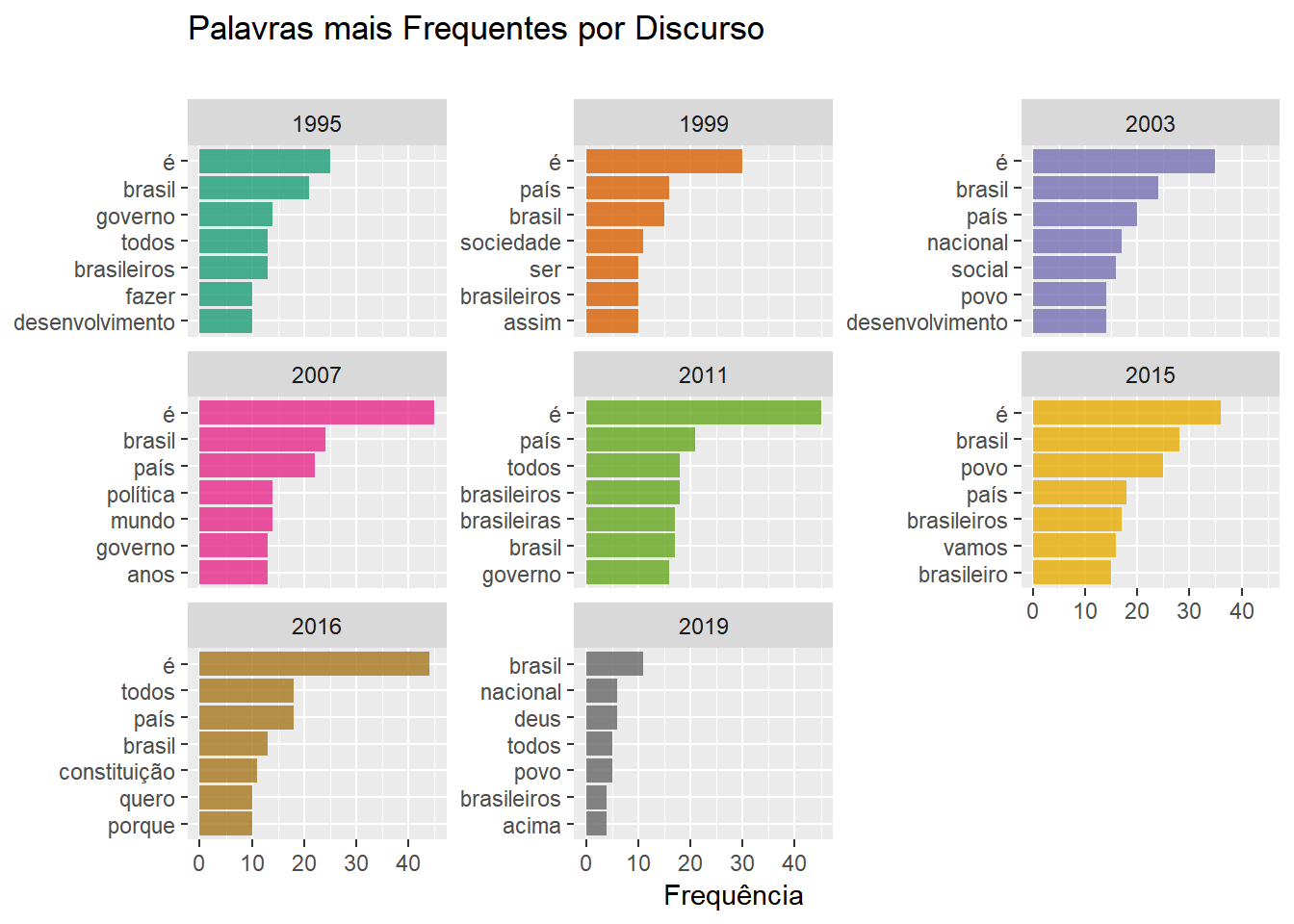
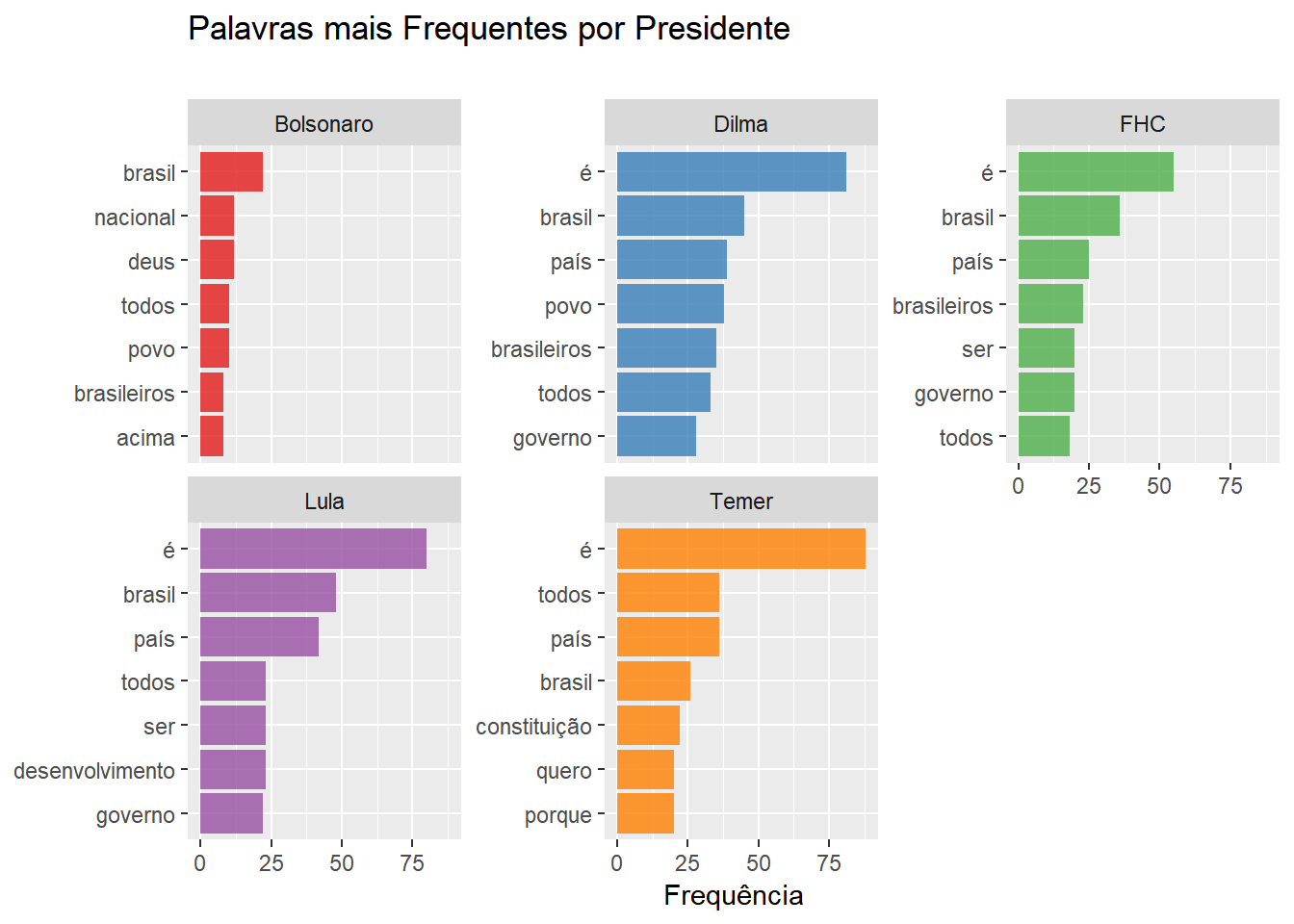
)Também mostramos as sete palavras mais faladas em cada discurso e por cada presidente e, em caso de empate, eliminamos arbitrariamente alguns dos ‘últimos’ elementos, usando a função slice unicamente para melhorar a vizualização. Aqui temos um exemplo de gráfico que, na divisão por presidente, não é estritamente nescessário multiplicar as métricas de Temer e Bolsonaro, uma vez que essas são computadas independentemente umas das outras. Aqui o fizemos, novamente por motivos estéticos. (experimente os efeitos de comentar as linhas indicadas abaixo)
# Palavras mais faladas por discurso
tidyfrase %>%
group_by(docs) %>%
count(word, docs, sort = TRUE) %>%
top_n(7) %>% # Me comente
slice(1:7) %>%
ungroup() %>%
mutate(term = reorder_within(word, n, docs)) %>%
ggplot(aes(term, n, fill = as.factor(docs))) +
geom_col(alpha = 0.8, show.legend = FALSE) +
facet_wrap(~docs, scales = "free_y") +
scale_fill_brewer(type = "qual", palette = "Dark2") +
coord_flip() +
scale_x_reordered() +
labs(
x = NULL, y = "Frequência",
title = "Palavras mais Frequentes por Discurso",
subtitle = " "
)
# Palavras mais faladas por presidente
tidyfrase %>%
group_by(presidas) %>%
count(word, presidas, sort = TRUE) %>%
mutate(n = n + (presidas == "temer" | presidas == "bolsonaro") * n) %>%
top_n(7) %>% # Me comente também
slice(1:7) %>%
ungroup() %>%
mutate(term = reorder_within(word, n, presidas)) %>%
ggplot(aes(term, n, fill = as.factor(presidas))) +
geom_col(alpha = 0.8, show.legend = FALSE) +
facet_wrap(~presidas, scales = "free_y", labeller = labeller(presidas = c(bolsonaro = "Bolsonaro", dilma = "Dilma", fhc = "FHC", lula = "Lula", temer = "Temer"))) +
scale_fill_brewer(type = "qual", palette = "Set1") +
coord_flip() +
scale_x_reordered() +
labs(
x = NULL, y = "Frequência",
title = "Palavras mais Frequentes por Presidente",
subtitle = " "
)
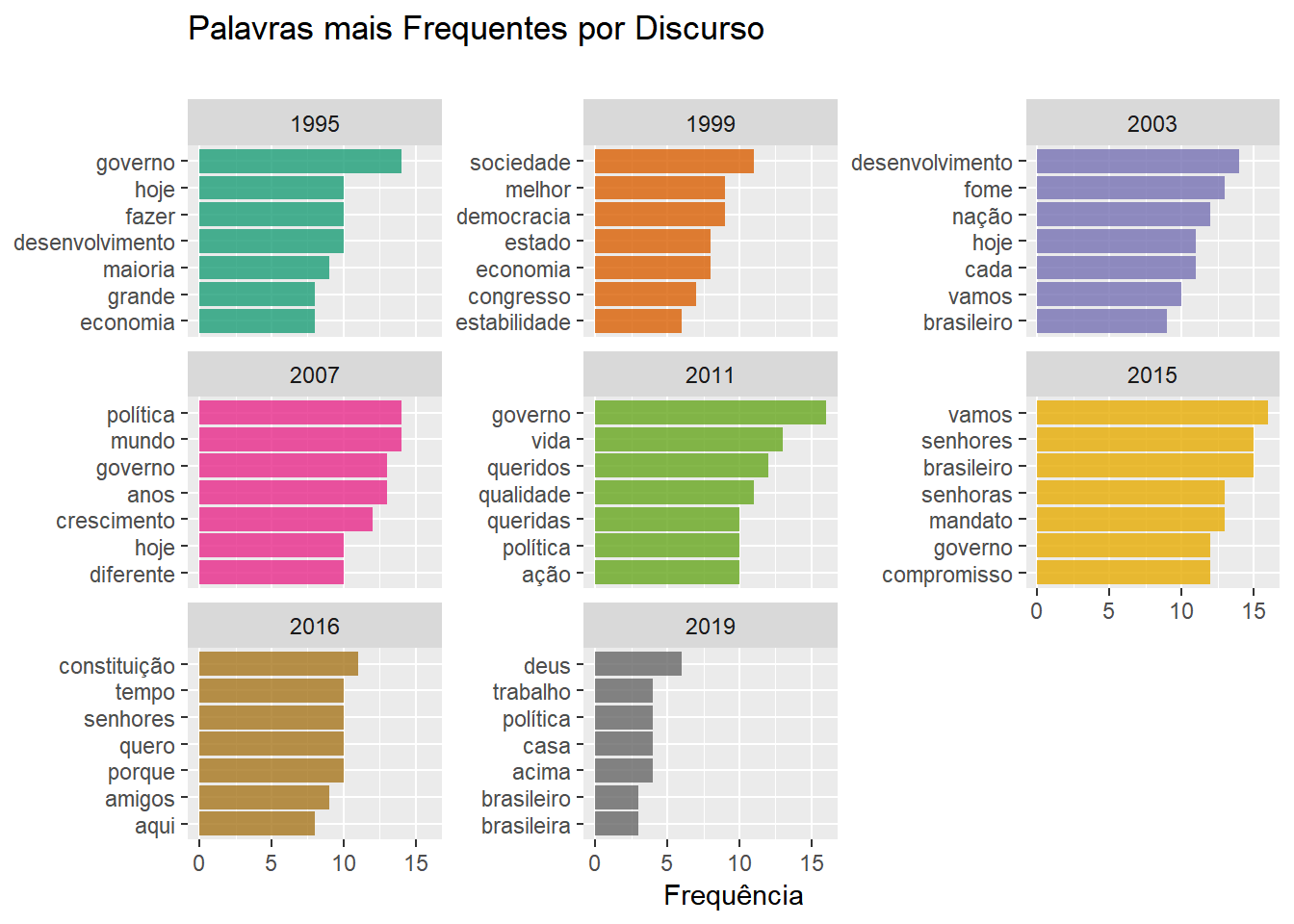
De certa forma, os gráficos acima confirmam a nossa impressão ao olhar as primeiras nuvens de palavras: existem palavras que se repetem muitas vezes num discurso presidencial por natureza. Esse fato nos atrapalha na tarefa de identificar as diferenças entre cada instância. Para lidar com esse problema, usamos uma técnica muito simples e surpreendentemente ,comum em análise automatizada de textos, que é eliminar sumariamente esses termos, esperando que os próximos no ranking tragam informações relevantes. Além disso, eliminamos as palavras “é”, “assim” e “ainda”. Finalmente, vamos eliminar palavras com três letras ou menos.
undesirable_words <- (((plot_total %>% select(word, n) %>% arrange(desc(n)))$word) %>% unique())[1:15]
undesirable_words <- c(as.character(undesirable_words), "é", "assim", "ainda")Vejamos a seguir os efeitos que essas mudanças produzem nos nossos resultados:
# Palavras mais faladas por discurso
tidyfrase %>%
filter(!(word %in% undesirable_words)) %>%
filter(nchar(word) > 3) %>%
group_by(docs) %>%
count(word, docs, sort = TRUE) %>%
top_n(7) %>% # Me comente
slice(1:7) %>%
ungroup() %>%
mutate(term = reorder_within(word, n, docs)) %>%
ggplot(aes(term, n, fill = as.factor(docs))) +
geom_col(alpha = 0.8, show.legend = FALSE) +
facet_wrap(~docs, scales = "free_y") +
scale_fill_brewer(type = "qual", palette = "Dark2") +
coord_flip() +
scale_x_reordered() +
labs(
x = NULL, y = "Frequência",
title = "Palavras mais Frequentes por Discurso",
subtitle = " "
)
# Palavras mais faladas por presidente
tidyfrase %>%
filter(!(word %in% undesirable_words)) %>%
filter(nchar(word) > 3) %>%
group_by(presidas) %>%
count(word, presidas, sort = TRUE) %>%
mutate(n = n + (presidas == "temer" | presidas == "bolsonaro") * n) %>%
top_n(7) %>%
slice(1:7) %>%
ungroup() %>%
mutate(term = reorder_within(word, n, presidas)) %>%
ggplot(aes(term, n, fill = as.factor(presidas))) +
geom_col(alpha = 0.8, show.legend = FALSE) +
facet_wrap(~presidas, scales = "free_y", labeller = labeller(presidas = c(bolsonaro = "Bolsonaro", dilma = "Dilma", fhc = "FHC", lula = "Lula", temer = "Temer"))) +
scale_fill_brewer(type = "qual", palette = "Set1") +
coord_flip() +
scale_x_reordered() +
labs(
x = NULL, y = "Frequência",
title = "Palavras mais Frequentes por Presidente",
subtitle = " "
)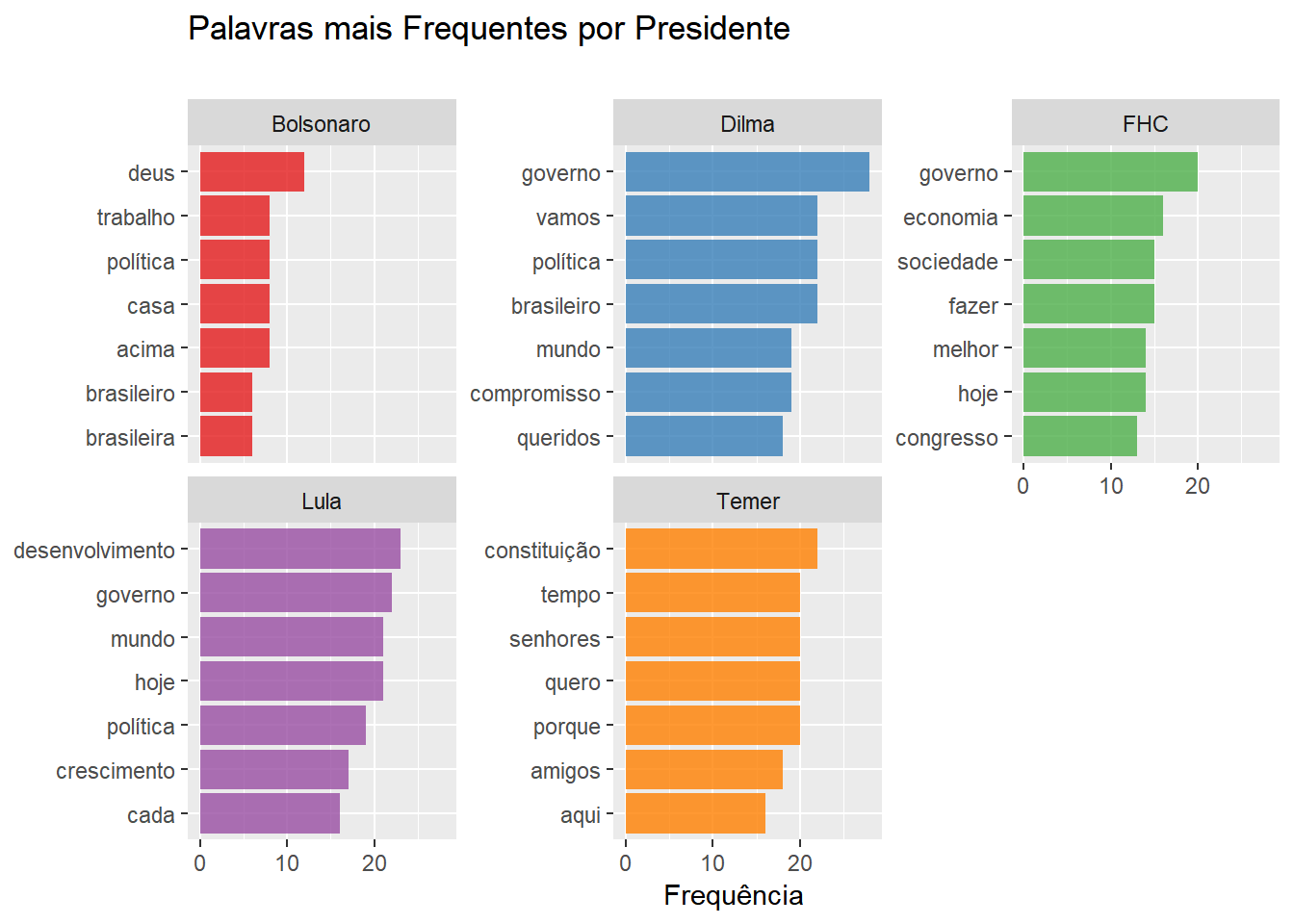
À primeira vista, parece que nossa última filtragem produziu resultados positivos em termos de informação. Adotaremos esse procedimento em muitos lugares daqui em diante.
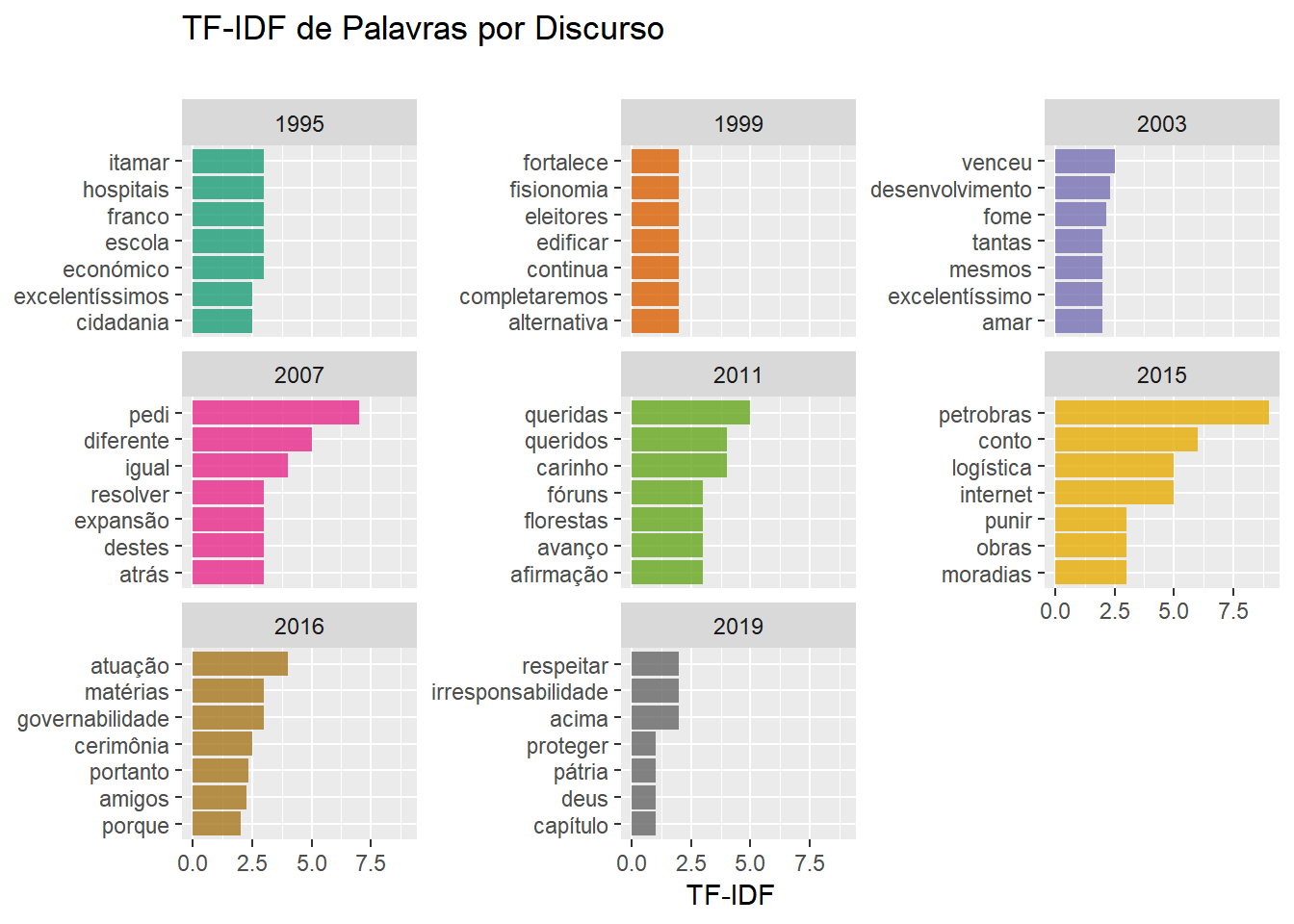
A Estatística TF-IDF
Finalmente chegou a hora de incorporar a estatística TF-IDF, que já citamos acima, na nossa análise. O TF-IDF de uma palavra em relação a um texto em um conjunto de documentos é dado pelo número de aparições dessa palavra no texto dividido pelo número de documentos em que a palavra aparece. O número de aparições de uma palavra idealmente indica sua importância dentro de um texto. Em contrapartida, o número de textos em que a palavra aparece indica a importância da palavra no contexto dos documentos. Sendo assim, essa medida quantifica o quão importante um palavra é para um texto em particular, dentro de um conjunto de documentos. Se temos um conjunto de \(i=1,\cdots,n\) textos, então o TF-IDF da palavra \(w\) no texto \(i\) é dado por \[T_i(w)=\frac{N_i(w)}{K(w)}.\]
Onde \(N_i(w)\) é o número de vezes que a palavra \(w\) aparece no texto \(i\) e \(K(w)\) é o número de documentos que contém \(w\). Daqui pra frente, nos aproveitaremos dessa ideia das mais diversas formas. A maneira mais natural de usar o TF-IDF no nosso contexto é considerar que cada discurso é um documento, de modo que medimos as palavras relevantes em cada documento. Uma pequena variação dessa linha de pensamento se dá ao considerarmos cada presidente em si um documento, assim mensuramos a importância dada por cada pessoa aos termos.
## TF-IDF de PALAVRAS POR DISCURSO
tfrases2 <- tidyfrase %>%
filter(!(word %in% undesirable_words)) %>%
filter(nchar(word) > 3) %>%
group_by(docs) %>%
count(word, docs, sort = TRUE) %>%
tf_idf_caseirao()
tfrases2 %>%
top_n(7) %>%
slice(1:7) %>%
ungroup() %>%
mutate(term = reorder_within(word, tf_idf, docs)) %>%
ggplot(aes(term, tf_idf, fill = as.factor(docs))) +
geom_col(alpha = 0.8, show.legend = FALSE) +
scale_fill_brewer(type = "qual", palette = "Dark2") +
facet_wrap(~docs, scales = "free_y") +
coord_flip() +
scale_x_reordered() +
labs(
x = NULL, y = "TF-IDF",
title = "TF-IDF de Palavras por Discurso",
subtitle = " "
)
# TF-IDF de PALAVRAS por presidente
tfrases <- tidyfrase %>%
filter(!(word %in% undesirable_words)) %>%
filter(nchar(word) > 3) %>%
group_by(presidas) %>%
count(word, presidas, sort = TRUE) %>%
tf_idf_caseirao() %>%
mutate(tf_idf = tf_idf + (presidas == "temer" | presidas == "bolsonaro") * tf_idf)
tfrases %>%
top_n(7) %>%
slice(1:7) %>%
ungroup() %>%
mutate(term = reorder_within(word, tf_idf, presidas)) %>%
ggplot(aes(term, tf_idf, fill = as.factor(presidas))) +
geom_col(alpha = 0.8, show.legend = FALSE) +
facet_wrap(~presidas, scales = "free_y", labeller = labeller(presidas = c(bolsonaro = "Bolsonaro", dilma = "Dilma", fhc = "FHC", lula = "Lula", temer = "Temer"))) +
scale_fill_brewer(type = "qual", palette = "Set1") +
coord_flip() +
scale_x_reordered() +
labs(
x = NULL, y = "TF-IDF",
title = "TF-IDF de Palavras por Presidente",
subtitle = " "
)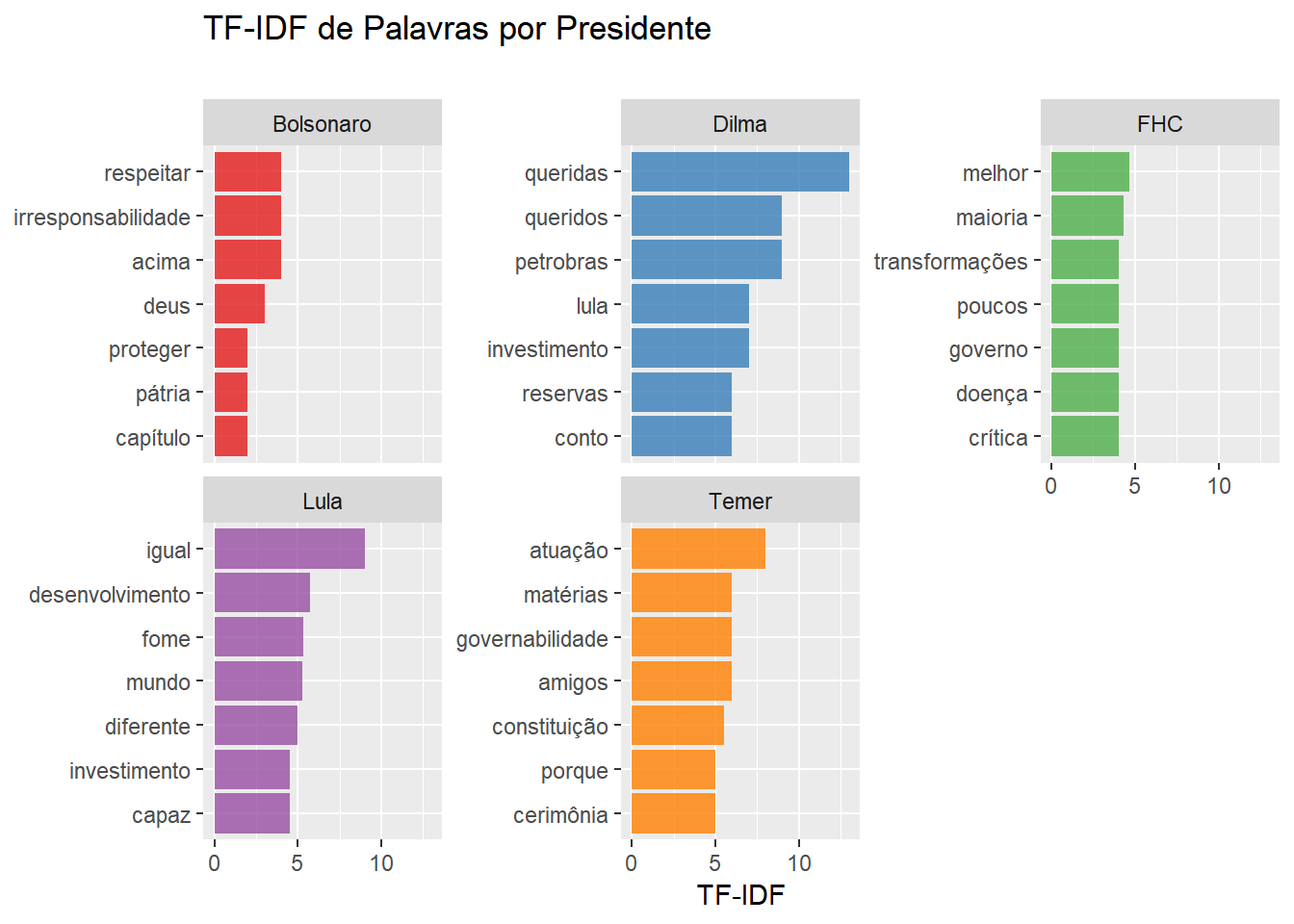
Em seguida, fizemos uma grande variedade de nuvens de palavras utilizando vários tipos de nuvens de palavras baseadas no TF-IDF das palavras, não incluímos esses resultados no texto para economizar um pouco da paciência do leitor.
# #Nuvem - numero abs - presidas
#
# pres<-unique(tfrases$presidas)
# for(i in 1:length(pres)){
# aux<-filter(as.data.frame(tfrases%>%ungroup()), presidas==pres[i])
# aux<-arrange(aux, desc(tf_idf))
# aux<- aux %>% group_by(presidas)
# aux<- aux %>% top_n(15) %>% ungroup()
# aux<-select(aux,word,tf_idf)
# ggwordcloud2(aux) %>% print()
#
# }
#
#
# #Nuvem - desvio padrão - ano
#
# anos<-unique(tfrases2$docs)
# for(i in 1:length(anos)){
# aux<-filter(as.data.frame(tfrases2%>%ungroup()), docs==anos[i])
# aux<-arrange(aux, desc(tf_idf))
# med<-mean(aux$tf_idf)
# sd<- sd(aux$tf_idf)
# aux<-aux %>% filter( tf_idf-med > 2*sd)
# aux<-select(aux,word,tf_idf)
# ggwordcloud2(aux) %>% print()
#
# }
#
#
# #Nuvem - abs- ano
#
# anos<-unique(tfrases2$docs)
# for(i in 1:length(anos)){
# aux<-filter(as.data.frame(tfrases2%>%ungroup()), docs==anos[i])
# aux<-arrange(aux, desc(tf_idf))
# aux<- aux %>% top_n(15)
# aux<-select(aux,word,tf_idf)
# ggwordcloud2(aux) %>% print()
#
# }
#Agora teremos várias ramificações na nossa análise. A ordenação dos tópicos daqui em diante foi projetada unicamente para preservar a harmonia entre as variáveis do código.
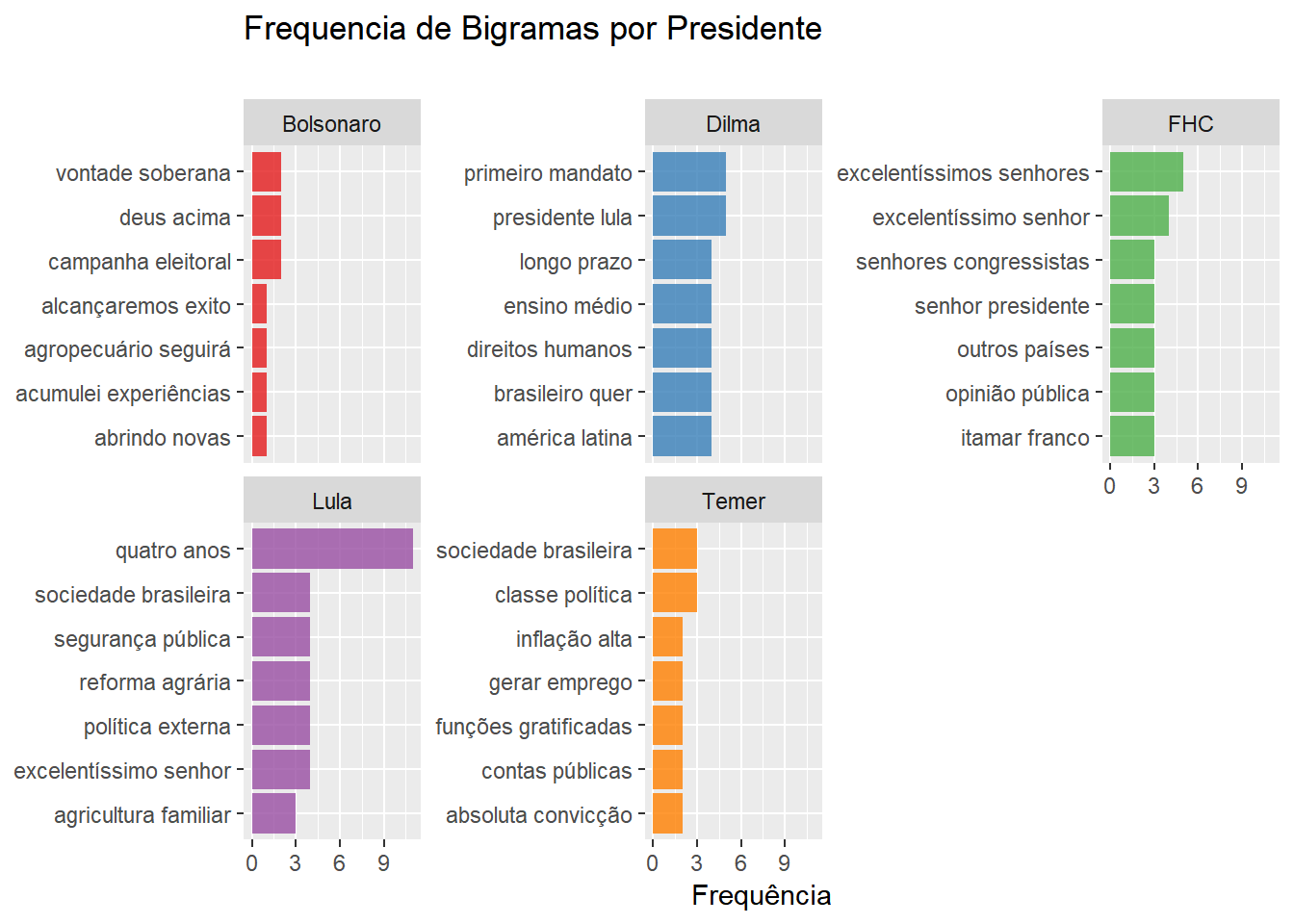
Bigramas
Acabamos de realizar uma análise descritiva relativamente simples dos discursos de posse desde 1995. Apesar disso, há de se destacar que toda a análise foi baseada apenas na frequência de palavras isoladas. O problema mais básico que surge nesse tipo de abordagem é desconsiderar completamente o contexto em que as palavras se encontram. Numa tentativa de lidar parcialmente com esse incoveniente, vamos agora análisar bigramas, que são conjuntos de duas palavras consecutivas em um texto. Em primeiro lugar vamos arrumar nossos dados, note que vamos usar a função unnest_tokens assim como no início. Sem ela nosso trabalho seria bem mais difícil!
## Bigramas - Organizando as Tabelas
bigrams <- tab_frase %>% select(frases, docs, presidas) %>% mutate(nfrase = row_number()) %>% unnest_tokens(bigram, frases, token = "ngrams", n = 2)
bigrams_separated <- bigrams %>%
separate(bigram, c("word1", "word2"), sep = " ")
## ADICIONAR OUTRAS PALAVRAS PARA FILTRAR????
bigrams_filter <- bigrams_separated %>%
filter(!(word1 %in% undesirable_words)) %>%
filter(nchar(word1) > 3) %>%
filter(!(word2 %in% undesirable_words)) %>%
filter(nchar(word2) > 3) %>%
filter(!(word1 %in% stp_wrds)) %>%
filter(!(word2 %in% stp_wrds))
bigrams_pres <- bigrams_filter %>%
filter(word1 != word2) %>%
unite(word, word1, word2, sep = " ", remove = FALSE) %>%
count(word, presidas, sort = TRUE) %>%
group_by(presidas)
bigrams_discursos <- bigrams_filter %>%
filter(word1 != word2) %>%
unite(word, word1, word2, sep = " ", remove = FALSE) %>%
count(word, docs, sort = TRUE) %>%
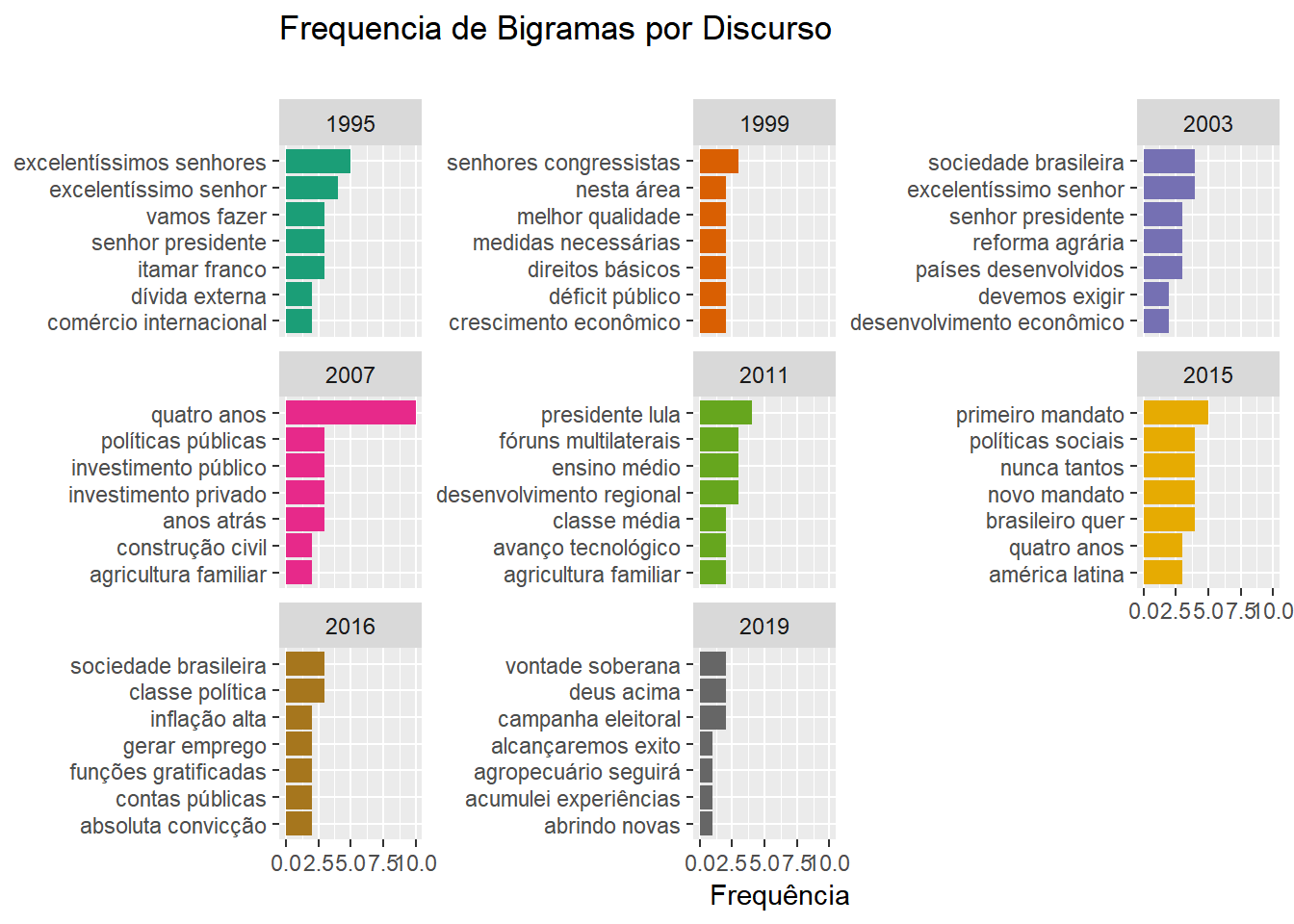
group_by(docs)Agora, vamos mostar gráficos de frequência de bigramas dividindo por discurso e presidente, exatamente como fizemos para palavras isoladas.
## Primeiros GRAFICOS - Frequencia de bigramas
bigrams_pres %>%
top_n(7) %>%
slice(1:7) %>%
ungroup() %>%
mutate(term = reorder_within(word, n, presidas)) %>%
ggplot(aes(term, n, fill = as.factor(presidas))) +
geom_col(alpha = 0.8, show.legend = FALSE) +
facet_wrap(~presidas, scales = "free_y", labeller = labeller(presidas = c(bolsonaro = "Bolsonaro", dilma = "Dilma", fhc = "FHC", lula = "Lula", temer = "Temer"))) +
scale_fill_brewer(type = "qual", palette = "Set1") +
coord_flip() +
scale_x_reordered() +
labs(
x = NULL, y = "Frequência",
title = "Frequencia de Bigramas por Presidente",
subtitle = " "
)
bigrams_discursos %>%
top_n(7) %>%
slice(1:7) %>%
ungroup() %>%
mutate(term = reorder_within(word, n, docs)) %>%
ggplot(aes(term, n, fill = as.factor(docs))) +
scale_fill_brewer(type = "qual", palette = "Dark2") +
geom_col(show.legend = FALSE) +
facet_wrap(~docs, scales = "free_y") +
coord_flip() +
scale_x_reordered() +
labs(
x = NULL, y = "Frequência",
title = "Frequencia de Bigramas por Discurso",
subtitle = " "
)
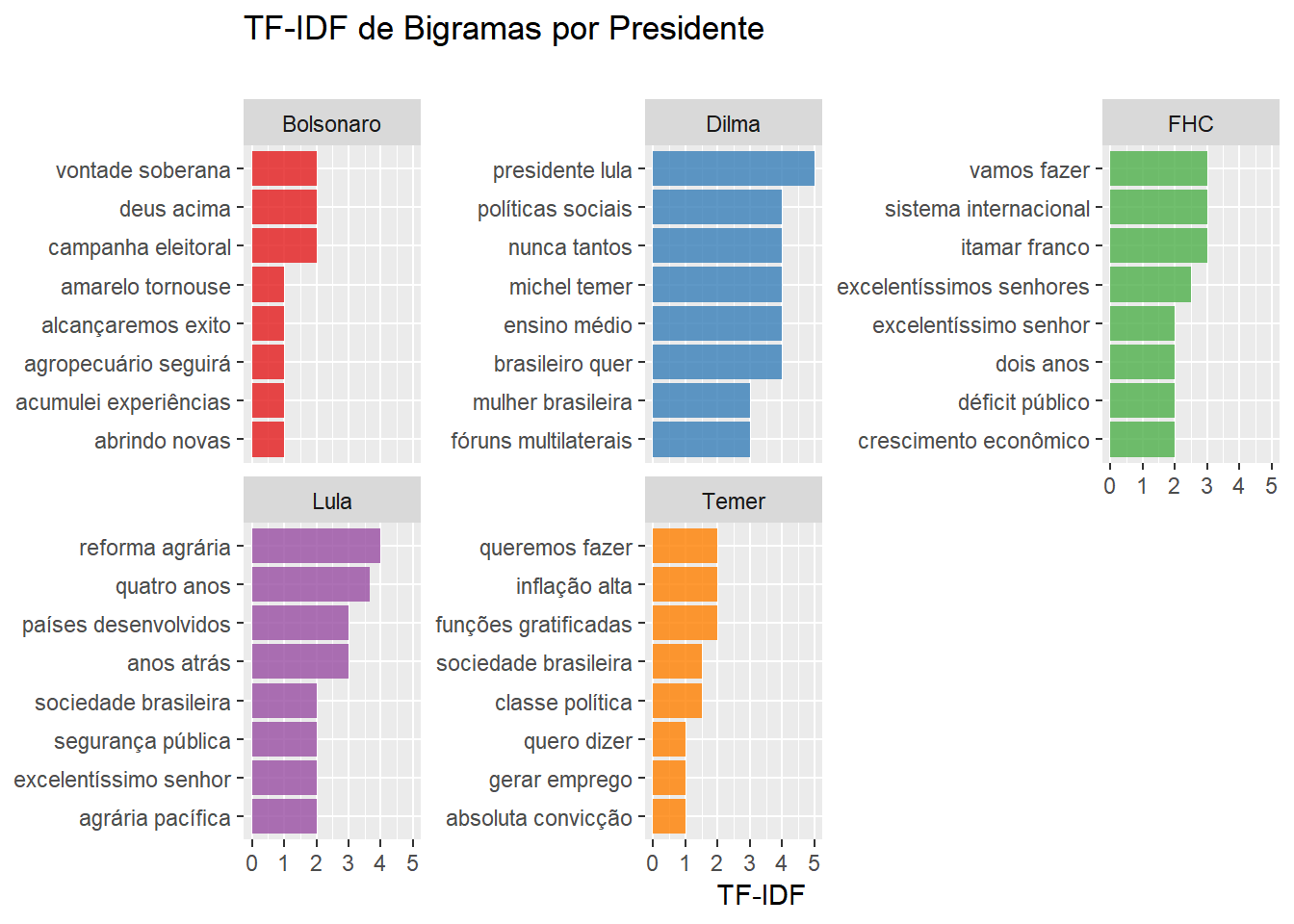
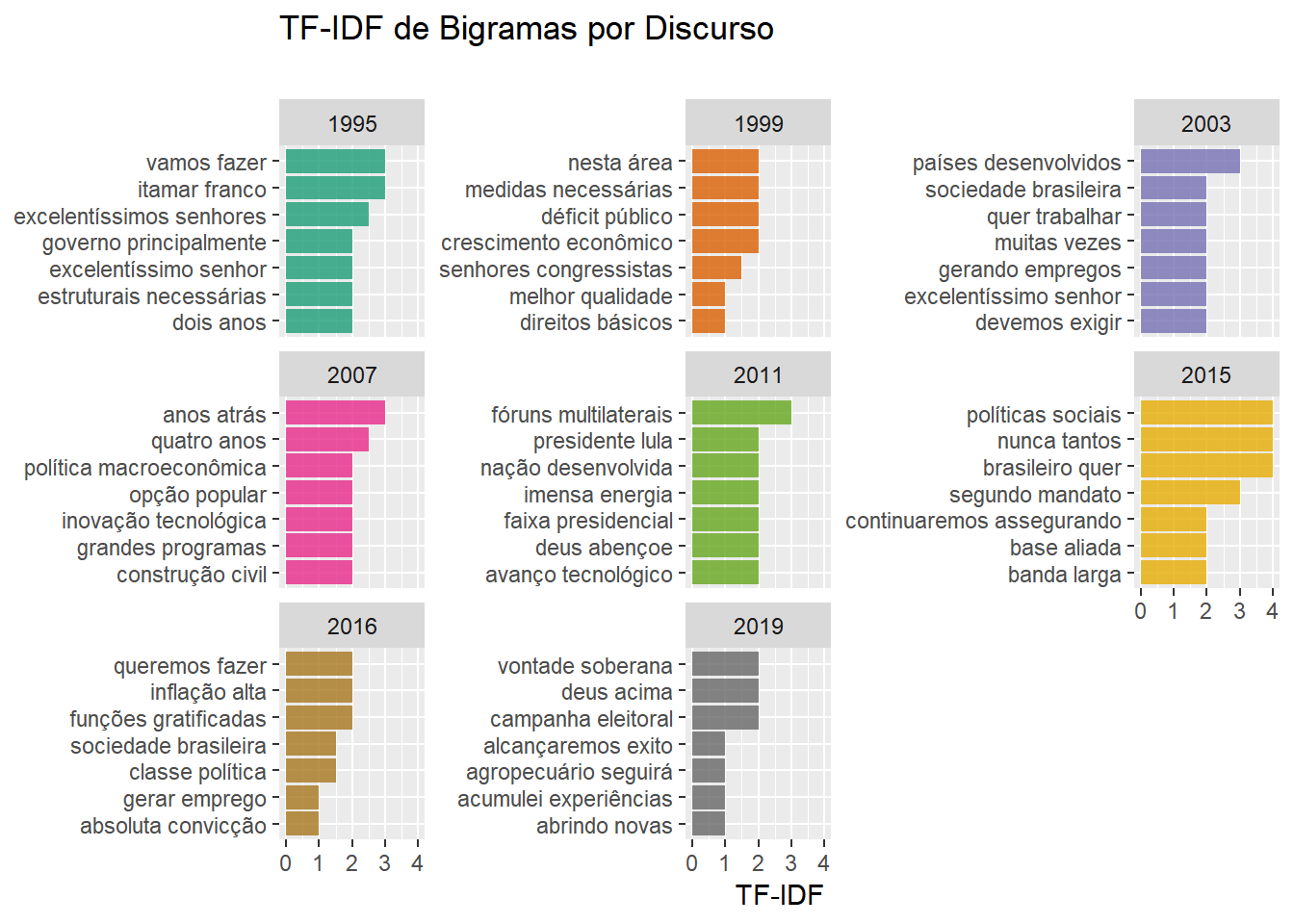
Também decidimos calcular o TF-IDF de bigramas num texto, por que não? A adaptação que fizemos no TF-IDF é bem pequena. Apenas utilizamos a frequência de bigramas ao invés da frequência de palavras.
## MAIS GRAFICOS - TD-IDF de Bigramas- pq nao?
bigramspres_tdidf <- bigrams_pres %>% tf_idf_caseirao()
bigramsdoc_tdidf <- bigrams_discursos %>% tf_idf_caseirao()
## GRAFICO BIGRAMAS-TF-IDF PRESIDENTE
bigramspres_tdidf %>%
top_n(8) %>%
slice(1:8) %>%
ungroup() %>%
mutate(term = reorder_within(word, tf_idf, presidas)) %>%
ggplot(aes(term, tf_idf, fill = as.factor(presidas))) +
geom_col(alpha = 0.8, show.legend = FALSE) +
facet_wrap(~presidas, scales = "free_y", labeller = labeller(presidas = c(bolsonaro = "Bolsonaro", dilma = "Dilma", fhc = "FHC", lula = "Lula", temer = "Temer"))) +
scale_fill_brewer(type = "qual", palette = "Set1") +
coord_flip() +
scale_x_reordered() +
labs(
x = NULL, y = "TF-IDF",
title = "TF-IDF de Bigramas por Presidente",
subtitle = ""
)
## GRAFICO BIGRAMAS-TD-IDF DISCURSO
bigramsdoc_tdidf %>%
top_n(7) %>%
slice(1:7) %>%
ungroup() %>%
mutate(
term = reorder_within(word, tf_idf, docs)
) %>%
ggplot(aes(term, tf_idf, fill = as.factor(docs))) +
geom_col(alpha = 0.8, show.legend = FALSE) +
facet_wrap(~docs, scales = "free_y") +
scale_fill_brewer(type = "qual", palette = "Dark2") +
coord_flip() +
scale_x_reordered() +
labs(
x = NULL, y = "TF-IDF",
title = "TF-IDF de Bigramas por Discurso",
subtitle = " "
)
Graf(ic)os
Grafos são uma excelente maneira de se vizualizar conexões entre objetos. Existe uma infinidade de possibilidades ao se representar dados desse modo. Pra começo de conversa, temos que escolher quem são os vértices e arestas do nosso grafo. Em segundo lugar, é preciso escolher o que significa dois objetos estarem conectados. Daí pra frente, existe um oceano de possibilidades: podemos decidir se existem ligações mais fortes que outras, se há direção ou simetria nas mesmas, se podemos conectar mais de dois vértices de uma só vez, entre tantas outras. No nosso contexto, duas das perguntas que podemos tentar responder com grafos incluem:
Considerando palavras como vértices e dado um conjunto de palavras-chave, quais são as palavras que mais aparecem associadas a elas? Nesse caso podemos, por exemplo, adotar a força da conexão entre duas palavras como a quantidade de bigramas em que duas palavras estão pareadas. Outra possibilidade seria calcular a força da conexão entre duas palavras como a razão entre o número de vezes em que cada palavra aparece versus o número de vezes que ela está pareada com a outra. Assim teríamos uma nova adaptação do TF-IDF para bigramaas.
Considerando presidentes ou discursos como vértices, qual é o nível de similaridade entre duas instâncias? Nesse caso, claramente teremos arestas com valores correspondentes à similaridade calculada entre dois textos. Na sequência discutiremos um pouco mais sobre como obter um valor númerico que represente semelhança entre documentos.
Em seguida iremos utilizar a biblioteca igraph para transformar um data.frame num grafo e o pacote ggraph para nossas vizualizações.
## GRAFO DE BIGRAMAS
palavras_chave <- c("acabar", "diminuir", "combater", "erradicar", "contra", "não", "pobreza", "violência", "fome", "medo")
bigrams_chave <- bigrams_separated %>%
filter(word1 %in% palavras_chave | word2 %in% palavras_chave) %>%
count(word1, word2, sort = TRUE) %>%
filter(!(word1 %in% stp_wrds | word2 %in% stp_wrds)) %>% ## VAI DE MORGAN CARAI
filter(!(word1 %in% undesirable_words | word2 %in% undesirable_words)) %>%
mutate(contribution = n) %>% # DA PRA FAZER UM ÍNDICE MAIS FERA AQUI
arrange(desc(abs(contribution))) %>%
group_by(word1) %>%
slice(seq_len(40)) %>%
arrange(word1, desc(contribution)) %>%
ungroup()
bigram_graph <- bigrams_chave %>%
graph_from_data_frame() # From `igraph`
set.seed(133)
a <- grid::arrow(type = "closed", length = unit(.15, "inches"))
ggraph(bigram_graph, layout = "fr") +
geom_edge_link(alpha = .25) +
geom_edge_density(aes(fill = n)) +
geom_node_point(color = "purple1", size = 1) + # Purple for Prince!
geom_node_text(aes(label = name), repel = TRUE) +
theme_void() + theme(
legend.position = "none",
plot.title = element_text(hjust = 0.5)
) +
ggtitle("Bigram Network")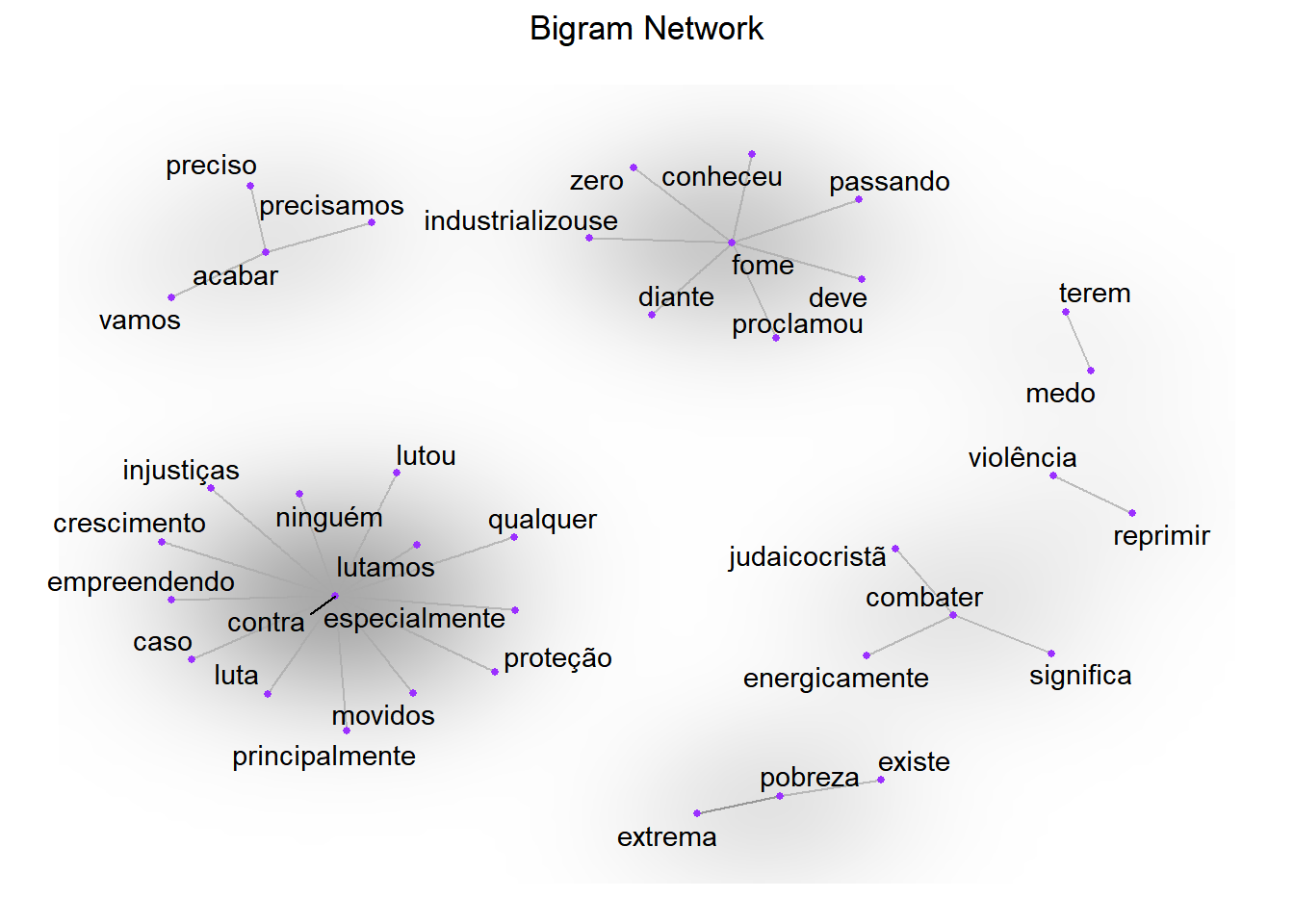
Redes de Similaridade
Uma coisa importante a se questionar sobre um conjunto de textos é o grau de similaridade entre eles. O principal empecilho que surge ao abordar esse problema é o de como quantificar a similaridade entre dois documentos. Uma primeira ideia seria contabilizar o número de palavras compartilhadas pelos textos. Entretanto, acreditamos que essa idéia pode ser melhor aproveitada para conjuntos de documentos maiores e mais variados, pois no nosso caso, teríamos muita similaridade entre todos os textos devido à natureza da ocasião. Alternativamente, vamos considerar o nível de similaridade entre dois textos com a soma do TF-IDF das palavras que aparecem em ambos. Quanto mais alto é esse número, mais palavras importantes são compartilhadas pelos textos.
## Via single words-docs##
## Cria data frame
textsimwdocs <- data.frame()
for (i in tfrases2$docs %>% unique()) {
for (j in tfrases2$docs %>% unique()) {
words1 <- (tfrases2 %>% filter(docs == i))$word %>% unique()
words2 <- (tfrases2 %>% filter(docs == j))$word %>% unique()
aux <- tfrases2 %>% filter(word %in% words1 && word %in% words2)
num <- sum(aux$tf_idf)
textsimwdocs <- rbind(textsimwdocs, c(i, j, num))
}
}
colnames(textsimwdocs) <- c("x1", "x2", "sim")
textsimwdocs <- textsimwdocs %>% filter(textsimwdocs$x1 != textsimwdocs$x2)
## GRAFO
similarity_graphwdocs <- textsimwdocs %>%
graph_from_data_frame() # From `igraph`
set.seed(1)
a <- grid::arrow(type = "closed", length = unit(.15, "inches"))
ggraph(similarity_graphwdocs, layout = "fr") +
geom_edge_link(alpha = .8) +
geom_edge_link(aes(edge_colour = (sim / 10000000), edge_width = 5)) +
scale_edge_colour_gradient(
low = "#3d45be", high = "#db423d",
space = "Lab", na.value = "grey50", guide = "edge_colourbar"
) +
geom_node_point(color = "black", size = 5) +
geom_node_text(aes(label = name), repel = TRUE) +
theme_void() + theme(
legend.position = "none",
plot.title = element_text(hjust = 0.5)
) +
ggtitle("Rede de Similaridade Baseada no TF-IDF de Palavras")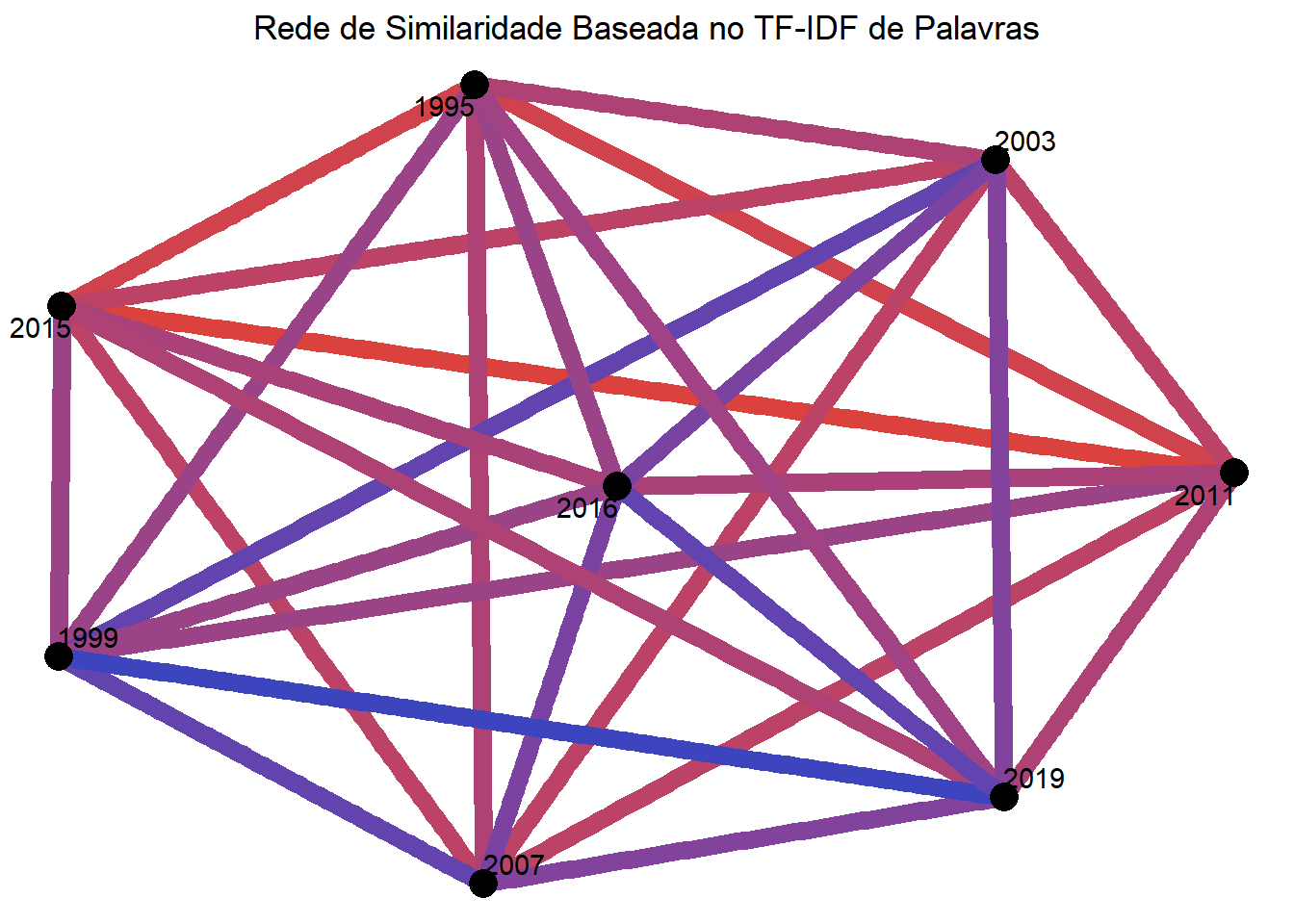
## Via presidents
## Duplicar Temer e bonoro
tfrases <- tfrases %>%
mutate(tf_idf = tf_idf + (presidas == "temer" | presidas == "bolsonaro") * tf_idf)
tfrases$presidas <- tfrases$presidas %>% as.character()
# Cria data frame
textsimwpres <- data.frame()
pr <- tfrases$presidas %>% unique()
for (i in 1:length(pr)) {
for (j in 1:length(pr)) {
words1 <- (tfrases %>% filter(presidas == pr[i]))$word %>% unique()
words2 <- (tfrases %>% filter(presidas == pr[j]))$word %>% unique()
aux <- tfrases %>% filter(word %in% words1 & word %in% words2)
num <- sum(aux$tf_idf)
textsimwpres <- rbind(textsimwpres, c(i, j, num))
}
}
colnames(textsimwpres) <- c("x1", "x2", "sim")
textsimwpres <- textsimwpres %>% filter(textsimwpres[, 1] != textsimwpres[, 2])
# GRAFO
similarity_graphwpres <- textsimwpres %>%
graph_from_data_frame() # From `igraph`
set.seed(1)
a <- grid::arrow(type = "closed", length = unit(.15, "inches"))
ggraph(similarity_graphwpres, layout = "fr") +
geom_edge_link(alpha = .8) +
geom_edge_link(aes(edge_colour = (sim / 10000), edge_width = 5)) +
scale_edge_colour_gradient(
low = "#3d45be", high = "#db423d",
space = "Lab", na.value = "grey50", guide = "edge_colourbar"
) +
geom_node_point(color = "black", size = 5) +
geom_node_text(aes(label = c("Dilma", "Lula", "FHC", "Temer", "Bolsonaro")), repel = TRUE) +
theme_void() + theme(
legend.position = "none",
plot.title = element_text(hjust = 0.5)
) +
ggtitle("Rede de Similaridade Baseada no TF-IDF de Palavras")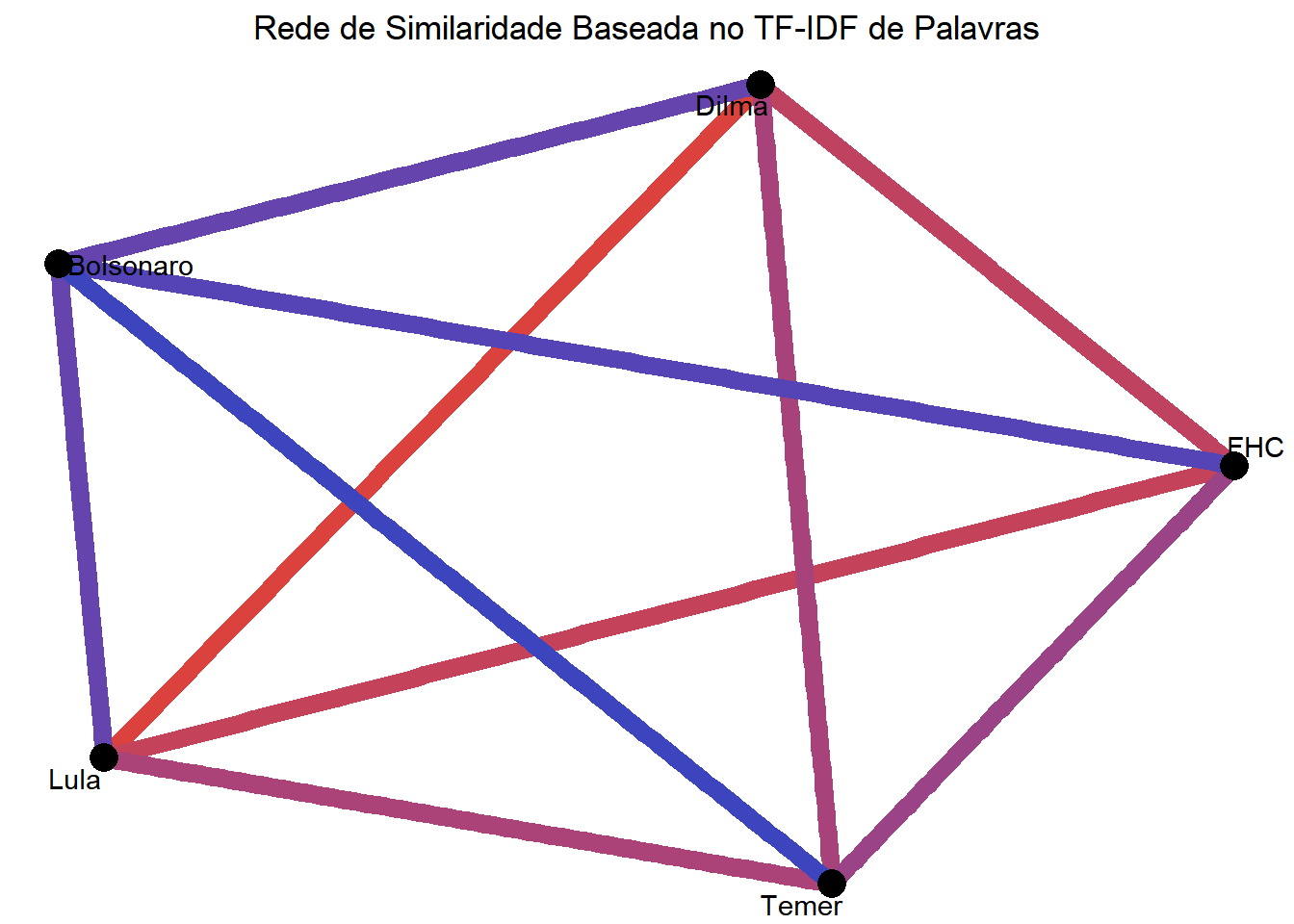
Agora vamos experimentar fazer outras redes de similaridade, mas desta vez vamos partir do TF-IDF de bigramas que calculamos recentemente e aplicar exatamente os mesmos meios usados acima.
# Similaridade Via Bigramas-Docs
textsimbdocs <- data.frame()
for (i in bigramsdoc_tdidf$docs %>% unique()) {
for (j in bigramsdoc_tdidf$docs %>% unique()) {
words1 <- (bigramsdoc_tdidf %>% filter(docs == i))$word %>% unique()
words2 <- (bigramsdoc_tdidf %>% filter(docs == j))$word %>% unique()
aux <- bigramsdoc_tdidf %>% filter(word %in% words1 && word %in% words2)
num <- sum(aux$tf_idf)
textsimbdocs <- rbind(textsimwdocs, c(i, j, num))
}
}
colnames(textsimbdocs) <- c("x1", "x2", "sim")
textsimbdocs <- textsimbdocs %>% filter(textsimbdocs$x1 != textsimbdocs$x2)
similarity_graphbdocs <- textsimbdocs %>%
graph_from_data_frame() # From `igraph`
set.seed(1)
a <- grid::arrow(type = "closed", length = unit(.15, "inches"))
ggraph(similarity_graphbdocs, layout = "fr") +
geom_edge_link(alpha = .8) +
geom_edge_link(aes(edge_colour = (sim / 10000000), edge_width = 5)) +
scale_edge_colour_gradient(
low = "#3d45be", high = "#db423d",
space = "Lab", na.value = "grey50", guide = "edge_colourbar"
) +
geom_node_point(color = "black", size = 5) +
geom_node_text(aes(label = name), repel = TRUE) +
theme_void() + theme(
legend.position = "none",
plot.title = element_text(hjust = 0.5)
) +
ggtitle("Rede de Similaridade Baseada no TF-IDF de Bigramas")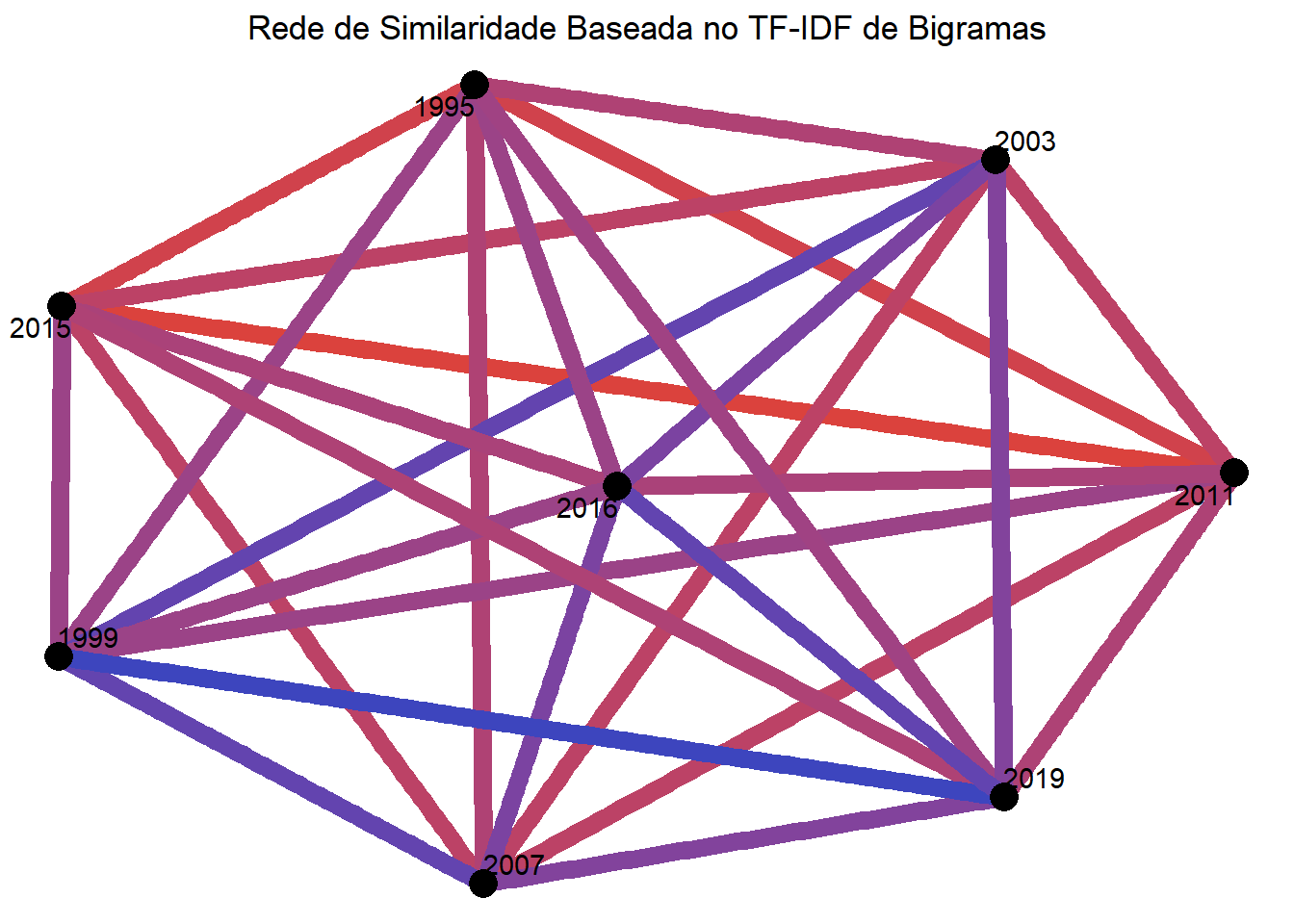
## Via presidents
bigramspres_tdidf <- bigramspres_tdidf %>%
mutate(tf_idf = tf_idf + (presidas == "temer" | presidas == "bolsonaro") * tf_idf)
bigramspres_tdidf$presidas <- bigramspres_tdidf$presidas %>% as.character()
textsimbpres <- data.frame()
prb <- bigramspres_tdidf$presidas %>% unique()
for (i in 1:length(prb)) {
for (j in 1:length(prb)) {
words1 <- (bigramspres_tdidf %>% filter(presidas == prb[i]))$word %>% unique()
words2 <- (bigramspres_tdidf %>% filter(presidas == prb[j]))$word %>% unique()
aux <- bigramspres_tdidf %>% filter(word %in% words1 & word %in% words2)
num <- sum(aux$tf_idf)
textsimbpres <- rbind(textsimbpres, c(i, j, num))
}
}
colnames(textsimbpres) <- c("x1", "x2", "sim")
textsimbpres <- textsimbpres %>% filter(textsimbpres[, 1] != textsimbpres[, 2])
similarity_graphbpres <- textsimbpres %>%
graph_from_data_frame() # From `igraph`
set.seed(1)
a <- grid::arrow(type = "closed", length = unit(.15, "inches"))
ggraph(similarity_graphbpres, layout = "fr") +
geom_edge_link(alpha = .8) +
geom_edge_link(aes(edge_colour = (sim / 10000), edge_width = 5)) +
scale_edge_colour_gradient(
low = "#3d45be", high = "#db423d",
space = "Lab", na.value = "grey50", guide = "edge_colourbar"
) +
geom_node_point(color = "black", size = 5) +
geom_node_text(aes(label = c("Dilma", "Lula", "FHC", "Temer", "Bolsonaro")), repel = TRUE) +
theme_void() + theme(
legend.position = "none",
plot.title = element_text(hjust = 0.5)
) +
ggtitle("Rede de Similaridade Baseada no TF-IDF de Bigramas")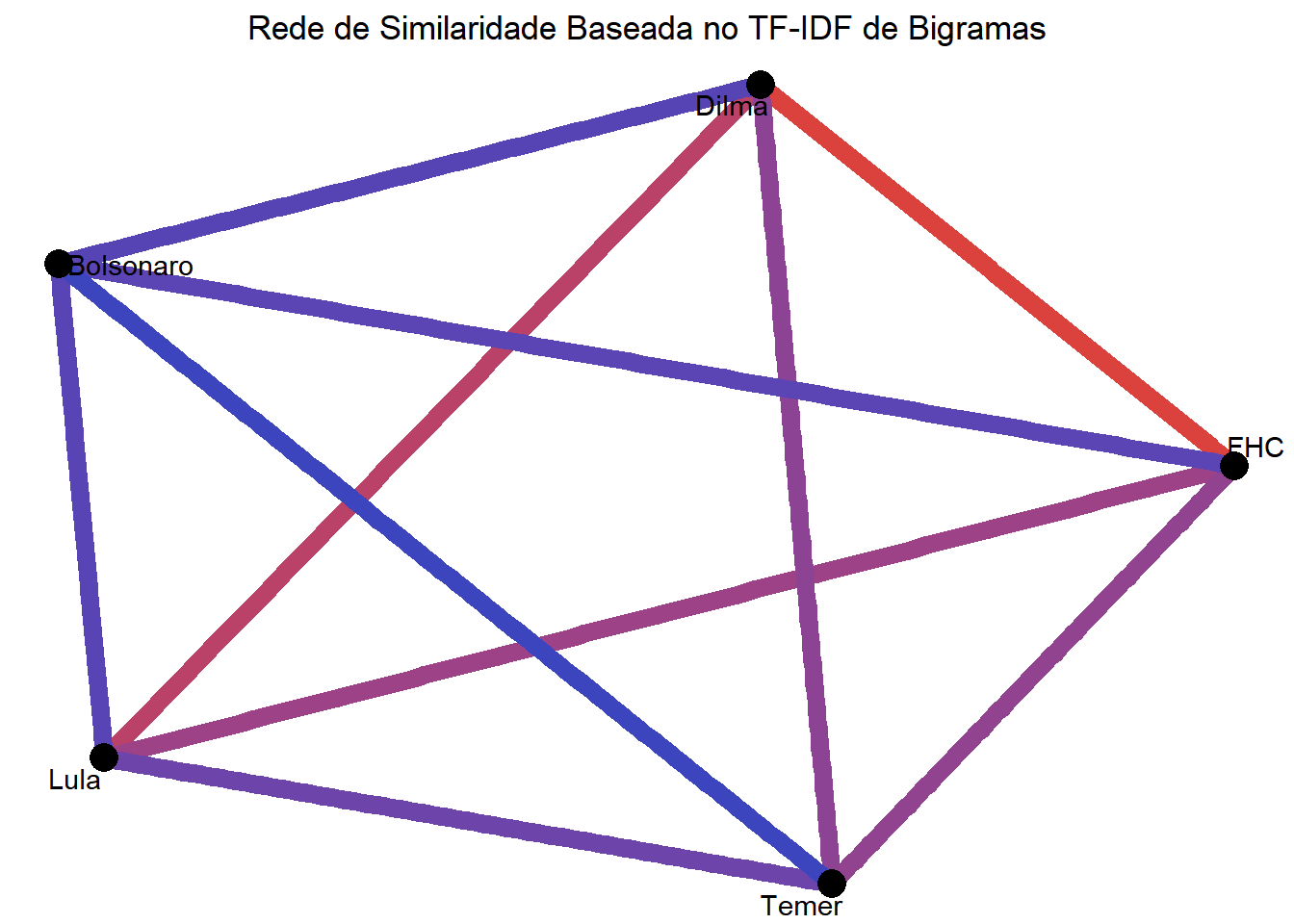
Considerações Finais
A única constante no universo é a mudança. Ou seja, esse texto pode ser editado/ampliado a qualquer momento. Pedimos ao leitor que nos envie dúvidas, críticas e/ou sugestões para seguirmos melhorando. Nesse link você pode encontrar o código, dados e imagens que utilizamos aqui. Obrigado por ter lido!